Nucleic acids—DNA and RNA—are macromolecules consisting of repeating nucleotides.
Nucleic Acid Simple Representation
DNA
DNA or deoxyribonucleic acid, directs the synthesis of proteins in an organism.
Nucleic acid and nucleotides are components of DNA. DNA contains the coded genetic program with instructions an organism’s specific heredity. DNA consists of segments, called genes. Specific proteins are responsible for each gene’s construction.
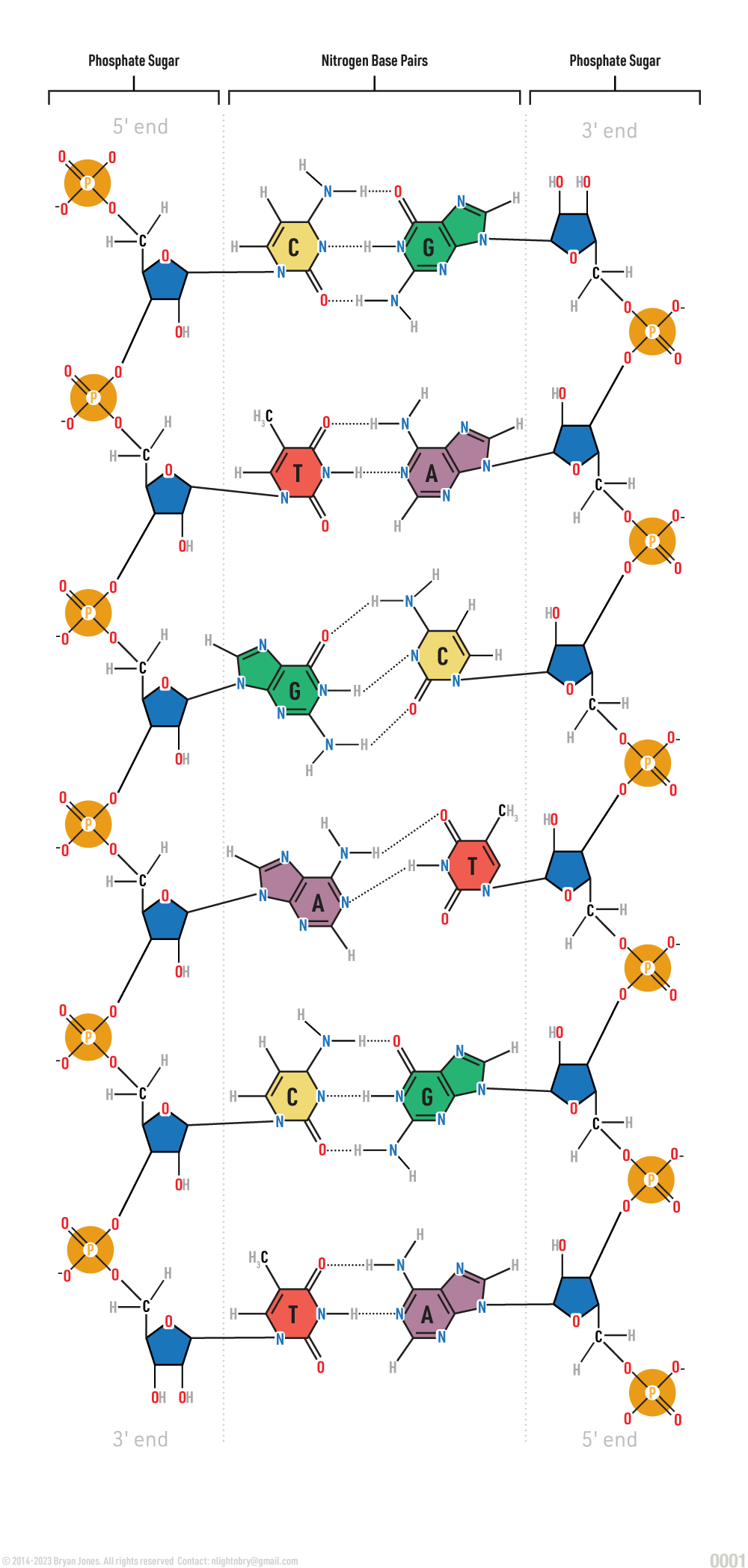
DNA and RNA are polymers, or chains, of repeating units called nucleotides, each of which is composed of three smaller units: a nitrogen base, a pentose (5-carbon) sugar, and a phosphate. The sugar and phosphate are called the backbone of DNA and RNA.
DNA Helix
DNA Helix
DNA Structure Strand
DNA Structure unwound with scale
DNA Structure unwound
DNA Structure unwound
Nucleic Acid Structure
Nucleic acids are the main pieces of DNA and RNA.
DNA (deoxyribonucleic acid) and ribonucleic acid (RNA) are both nucleic acids because they were discovered in the nucleus of a cell. Nucleotides are organic molecules which serve as monomers, or subunits, of nucleic acids.
Structure of a nucleotide:
Structure of a nucleotide
Graphic representation of the structure of DNA & RNA.
Graphic representation of the structure of DNA
Nucleotide Composition
A nucleotide is composed of a phosphate group, a sugar, and a nitrogenous base.
Nitrogenous Base
Simplified representation of nucleic bases
Each nucleotide has three parts: a nitrogen-containing base, a pentose (five-carbon) sugar (either deoxyribose or ribose), and a phosphate group (phosphoric acid). The nitrogen-containing bases (nitrogenous base) are compounds made up of carbon, hydrogen, oxygen, and nitrogen atoms. The bases are named adenine (A), thymine (T), cytosine (C), guanine (G), and uracil (U). A and G are double-ring structures called purines, whereas T, C, and U are single-ring structures referred to as pyrimidines.
Phosphate group (phosphoric acid):
Phosphate group (phosphoric acid):
Sugars:
Sugars:
Nitrogen bases:
Nitrogen bases:
〰️〰️〰️ represents the remainder molecule.
The Nitrogenous base A (Adenine) is paired with T (Thymine):
The Nitrogenous base A (Adenine) is paired with T (Thymine):
The Nitrogenous base G (Guanine) is paired with C (Cytosine):
The Nitrogenous base G (Guanine) is paired with C (Cytosine):
In RNA, the base A (adenine) is paired with U (uracil)
In RNA, the base A (adenine) is paired with U (uracil):
AT | Ball-and-Stick
AT | Ball-and-StickAT | Ball-and-Stick
AT | Ball-and-Stick
AT | Ball-and-StickAT | Ball-and-Stick
GC | Ball-and-Stick
GC | Ball-and-StickGC | Ball-and-Stick
GC | Ball-and-Stick
GC | Ball-and-StickGC | Ball-and-Stick
DNA | Ball-and-Stick
DNA | Ball-and-Stick
DNA | Ball-and-Stick
DNA | Ball-and-Stick
Functions of Nucleotides
Nucleotides can perform several different types of functions in a living cell.
Nucleotides can be chemical messengers, regulating cellular activities.
Nucleotides can, with one or two additional phosphates added, function as coenzymes which are essential parts of certain enzymes.
Nucleotides can carry energy from one part of a cell to another.
Certain types of nucleotides are components of nucleic acid.
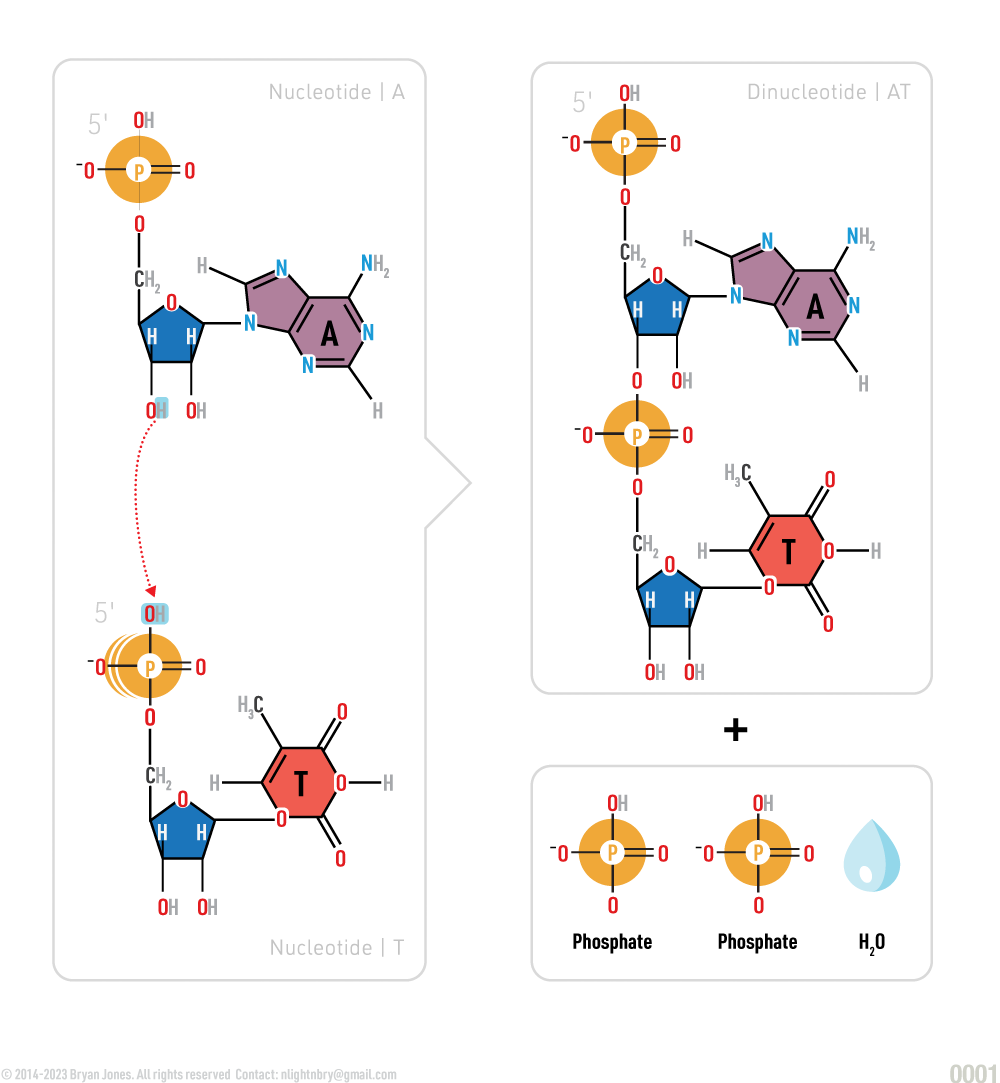
Adding Nucleotides
Adding a nucleotide to DNA:
Adding a nucleotide to DNA:
A condensation reaction links nucleotides:
A condensation reaction links nucleotides:
RNA
RNA, or ribonucleic acid is a diverse structure that's versatile and organizer of protein synthesis.
RNA comes in many shapes and sizes, with different functions. RNA is a single-stranded molecule that can fold into a variety of shapes, depending on its sequence. This diversity of structure gives RNA a wide range of functions.
RNA is another important nucleic acid and is required for the creation of proteins. RNA and DNA are similar in that they both consist of chains of nucleotides. They differ in that RNA is often a single strand, with the exception of certain specific viruses. Instead of deoxyribose, it contains the sugar ribose. It also contains uracil instead of the Thymine (T) found in DNA.
RNA’s major function is to synthesize protein. This is done through three major types of RNA: messenger RNA (mRNA) is a copy of a gene that provides the order and type of amino acids in a protein; transfer RNA (tRNA) is a carrier that delivers the correct amino acids for protein assembly; ribosomal RNA (rRNA) is a major component of ribosomes.
RNA's wide range of functions include:
Catalyzing chemical reactions
Regulating gene expression
Transporting molecules
RNA single-strand
RNA single-strand
RNA Structure:
RNA Structure with nucleic acid structural fromula on the left and simplified graphic representation of helix.
mRNA
mRNA stands for messenger ribonucleic acid. It is a single-stranded molecule of RNA that carries the instructions from DNA to the ribosomes, where proteins are made. mRNA is created in the nucleus of the cell, and then it travels to the cytoplasm where it is translated into proteins.
mRNA is essential for life, as it is responsible for the production of all proteins in the cell. Proteins are responsible for a wide variety of functions in the cell, including structure, metabolism, and cell signaling.
mRNA is also being used in new types of vaccines and gene therapies. mRNA vaccines work by introducing a piece of mRNA into the body that codes for a protein from a virus or bacteria. When the body's cells read this mRNA, they produce the protein, which the immune system then recognizes as foreign and attacks. This helps to train the immune system to fight off the virus or bacteria in the future.
Gene therapy is a treatment that uses genetic material to treat or cure a disease. mRNA gene therapy works by introducing a piece of mRNA into the body that codes for a protein that can correct a genetic defect. This can help to treat diseases such as cystic fibrosis, sickle cell anemia, and muscular dystrophy.
mRNA is a promising new technology with the potential to revolutionize the way we treat diseases. It is still under development, but it has the potential to save lives and improve the quality of life for millions of people.
Summary of key differences between DNA and mRNA:
Feature
DNA
mRNA
Structure
Double-stranded
Single-stranded
Location
Nucleus
Cytoplasm
Function
Stores genetic information
Carries genetic information from DNA to ribosomes
Role in protein synthesis
Provides the template for mRNA synthesis
Carries the instructions for protein synthesis to the ribosomes
mRNA Structure
Nucleic Acid mRNA Structure single-strand
tRNA
tRNA is an adapter molecule that brings amino acids to the ribosome during protein synthesis.
There are about 20 different types of tRNA molecules, one for each of the 20 amino acids.
tRNAs are transcribed from DNA in the nucleus of the cell.
tRNAs are then exported to the cytoplasm, where they participate in protein synthesis.
tRNAs are modified after transcription. These modifications are important for the function of the tRNA molecules.
tRNAs are very stable molecules. They can survive for several hours outside of the cell.
Transfer RNA (tRNA) is a small RNA molecule that plays a key role in protein synthesis. It is responsible for carrying amino acids to the ribosome, where they are assembled into proteins. Each tRNA molecule has a specific anticodon that binds to a complementary codon on the mRNA molecule. This allows the tRNA to deliver the correct amino acid to the ribosome.
tRNA molecules are typically about 70-100 nucleotides long and have a cloverleaf structure. The anticodon is located in the D-loop of the tRNA molecule. The amino acid is attached to the 3' end of the tRNA molecule
The first step in protein synthesis is for the ribosome to bind to the mRNA molecule. The ribosome then scans the mRNA molecule for a start codon, which is usually AUG. When the ribosome finds a start codon, it binds to a tRNA molecule that has an anticodon complementary to the start codon. This tRNA molecule carries the amino acid methionine, which is the first amino acid in most proteins.
The ribosome then moves along the mRNA molecule, adding one amino acid at a time. For each amino acid, the ribosome binds to a tRNA molecule that has an anticodon complementary to the next codon on the mRNA molecule. The amino acid from the tRNA is then transferred to the growing polypeptide chain.
This process continues until the ribosome reaches a stop codon. A stop codon does not code for any amino acid. When the ribosome reaches a stop codon, it releases the polypeptide chain and the tRNA molecules.
tRNAs are essential for protein synthesis. Without tRNAs, the ribosome would not be able to correctly assemble amino acids into proteins.
tRNA Structure
tRNA Structure | Pictorial Representation
tRNA is a small RNA molecule that is essential for protein synthesis. It has an anticodon sequence that binds to a complementary codon sequence on mRNA. This allows tRNA to bring the correct amino acid to the ribosome for incorporation into a growing protein chain.
tRNA Structure | Simplified
tRNA Structure | Simplified
tRNA
tRNA
tRNA & Amino acid Charging
Amino acid charging is the process by which aminoacyl-tRNA synthetases attach the appropriate amino acid to their corresponding tRNA molecules.
Amino acid charging is the process by which amino acids are activated and covalently linked to their cognate transfer RNA (tRNA) molecules in a process called aminoacylation or charging. This process is carried out by aminoacyl-tRNA synthetases, which are enzymes that catalyze the formation of an ester bond between the carboxyl group of the amino acid and the 3'-OH group of the tRNA. Aminoacyl-tRNA synthetases are highly specific for both the amino acid and the tRNA that they recognize, ensuring that the correct amino acid is linked to the appropriate tRNA. This step is essential for protein synthesis since the correct amino acid must be incorporated into the growing peptide chain according to the genetic code.
Amino acid charging steps
tRNA
Graphic Representation of tRNA, amino acid attachment site, codon
1 | A specific amino acid and ATP bind to the aminoacyl-tRNA synthetase.
A specific amino acid and ATP bind to the aminoacyl-tRNA synthetase.
2 | The amino acid is activated by the covalent bonding of AMP
The amino acid is activated by the covalent bonding of AMP
3 | The amino acid is activated by the covalent bonding of AMP, and pyrophosphate group is released.
Pyrophosphate group is released.
4 | The correct tRNA binds to the synthetase.
The correct tRNA binds to the synthetase.
5 | The amino acid is covalently attached to the tRNA.
The amino acid is covalently attached to the tRNA.
6 | AMP is released.
AMP is released.
7 | The charged tRNA is released
The charged tRNA is released
1ffy | Isoleucyl-tRNA-Synthase
Noodle chair for tRNA
The charged Isoleucyl tRNA is released
1qf6 | Threonyl-tRNA Synthase
tRNA stuck to a Rice Crispy treat.
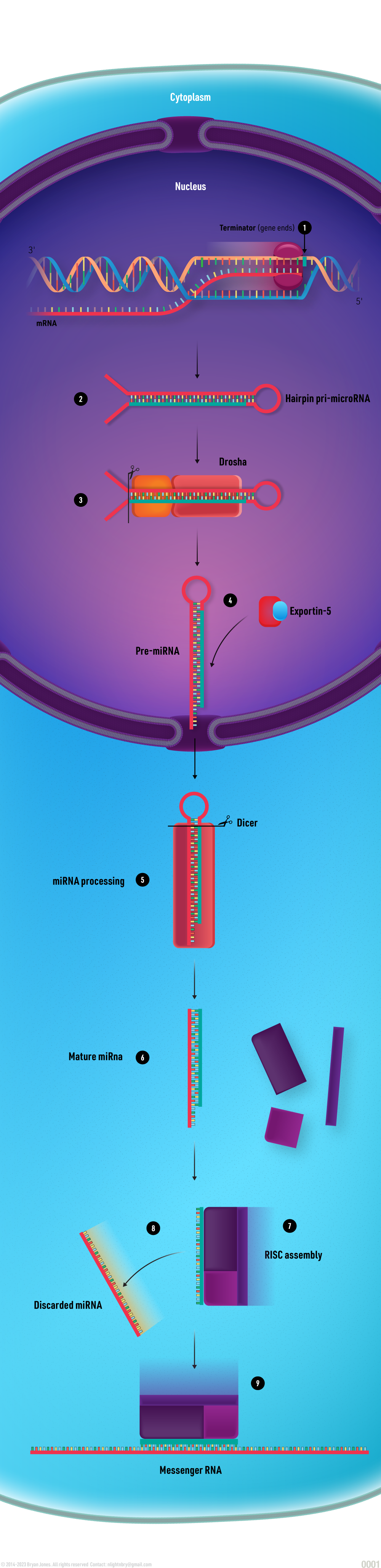
MicroRNA
MicroRNAs are a rapidly growing area of research and their role in human health is still being explored. However, it is clear that they play important roles in regulating gene expression and many diseases.
Basic MicroRNA Structure
MicroRNA Structure
MicroRNAs (miRNAs) are small, non-coding RNA molecules that play important roles in regulating gene expression. They are about 22 nucleotides long and are found in all eukaryotes, including plants, animals, and humans. miRNAs are transcribed from DNA sequences into primary miRNAs (pri-miRNAs), which are then processed into precursor miRNAs (pre-miRNAs) and mature miRNAs. Mature miRNAs bind to specific sequences in messenger RNA (mRNA) molecules, which can lead to the degradation of the mRNA or the inhibition of its translation into protein. This process is called RNA interference (RNAi).
miRNAs have been shown to regulate a wide variety of genes, including those involved in cell growth, differentiation, apoptosis, and metabolism. They are also involved in a number of diseases, including cancer, neurodegenerative disorders, and cardiovascular disease.
Here are some of the key functions of microRNAs
Regulating gene expression: miRNAs can control the expression of genes by binding to and degrading mRNA molecules. This can either increase or decrease the amount of protein produced from the gene.
Influencing cell growth and differentiation: miRNAs play a role in the development and differentiation of cells. They can also influence the proliferation and death of cells.
Promoting apoptosis: miRNAs can trigger apoptosis, which is a programmed cell death. This is important for removing damaged or unwanted cells from the body.
Regulating metabolism: miRNAs play a role in the regulation of metabolism. They can influence the production of enzymes and other molecules involved in energy production and storage.
Structural Possibilities of MicroRNA
GRAPHIC
Modification to miRNA
Modification to miRNA diagram
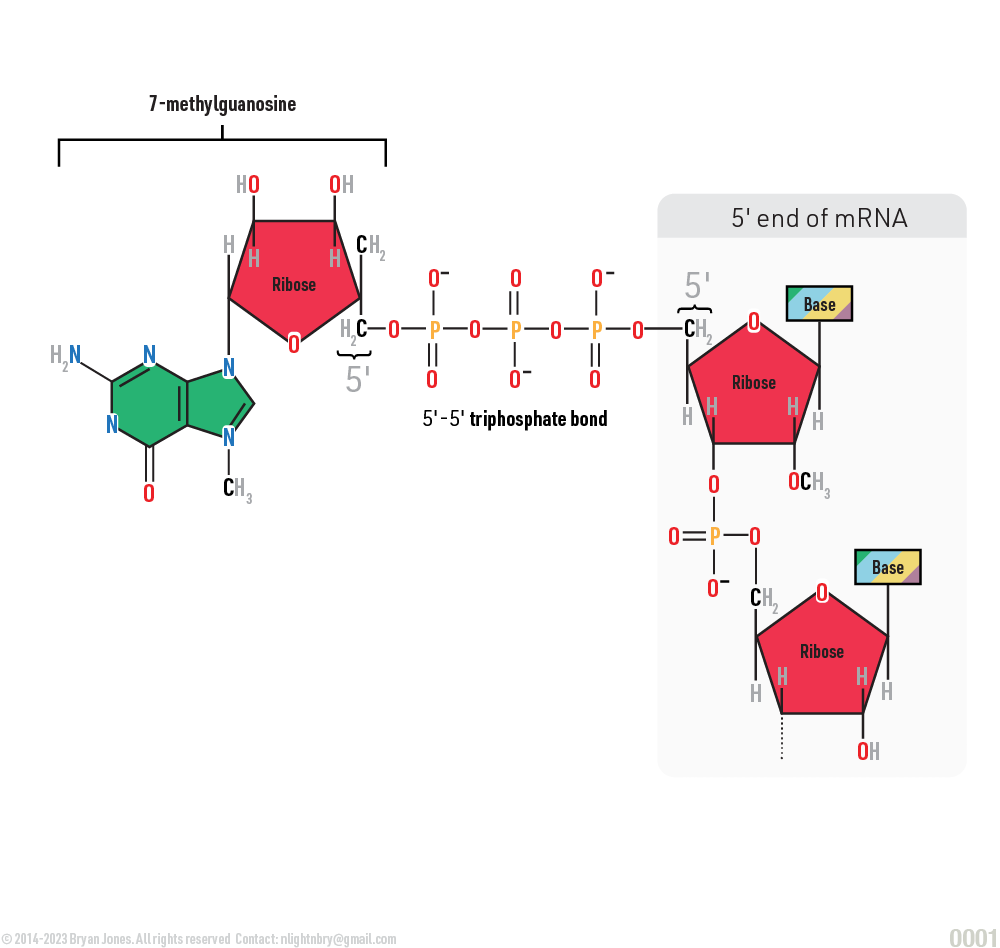
RNA Cap Structure
The cap structure consists of a 7-methylguanosine (m7G) linked via a 5' to 5' triphosphate bridge to the first transcribed nucleotide (X). The X can be any nucleotide, but is usually an adenosine (A).
The RNA cap structure is important for a number of reasons, including:
Protects the mRNA from degradation by enzymes.
Helps to recruit proteins that are involved in the translation of the mRNA into protein.
Helps to stabilize the mRNA structure.
Nucleic Acid mRNA Cap Structure
GRAPHIC
Nucleic Acid Terminology
Adding a nucleotide to DNA or RNA begins with Energy
Nucleoside: just the base, no additional structure
Nucleotide: A Nucleoside + Monosaccharide + Phosphate group which can be mono, di, or triphosphate
Nucleic Acid Variations
Nucleoside
Nucleotide
Nucleoside monophosphate
Nucleoside diphosphate
Nucleoside triphosphate
Deoxynucleoside
Adenine
Adenosine (AMP)
Adenosine monophosphate (AMP)
Adenosine diphosphate (ADP)
Adenosine triphosphate (ATP)
Deoxyadenosine (dAMP)
Guanine
Guanosine (GMP)
Guanosine monophosphate (GMP)
Guanosine diphosphate (GDP)
Guanosine triphosphate (GTP)
Deoxyguanosine (dGMP)
Cytosine
Cytidine (CMP)
Cytidine monophosphate (CMP)
Cytidine diphosphate (CDP)
Cytidine triphosphate (CTP)
Deoxycytidine (dCMP)
Thymine
Thymidine (TMP)
Thymidine monophosphate (TMP)
Thymidine diphosphate (TDP)
Thymidine triphosphate (TTP)
Deoxythymidine (dTMP)
Uracil
Uridine (UMP)
Uridine monophosphate (UMP)
Uridine diphosphate (UDP)
Uridine triphosphate (UTP)
-
Nucleic Acid Terminology
Adding a nucleotide to DNA or RNA begins with Energy
Nucleoside: just the base, no additional structure
Nucleotide: A Nucleoside + Monosaccharide + Phosphate group which can be mono, di, or triphosphate
Nucleic Acid Variations
Graphic representation of
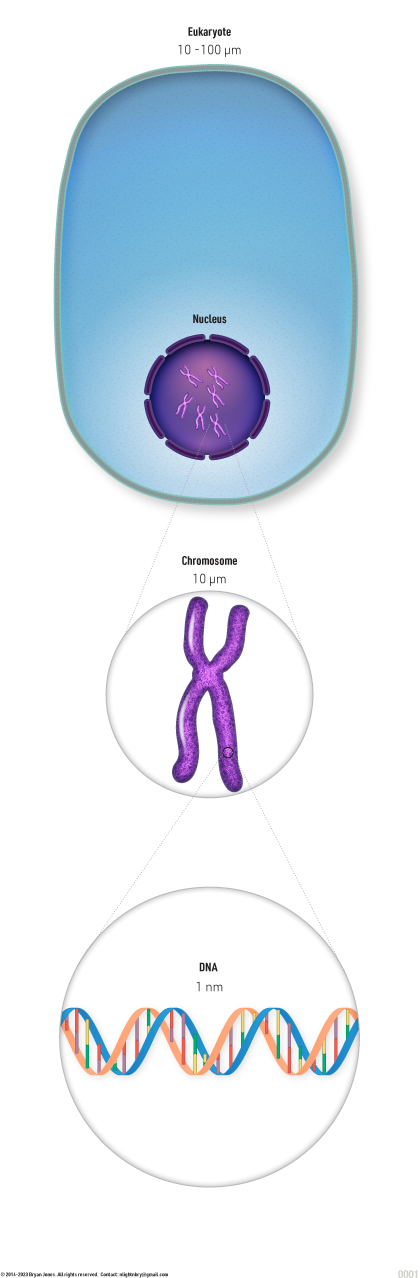
Genetic Material Locations
Nucleus, Chromosomes, Plasmids, Mitochondria
DNA:
In the nucleus of cells, DNA is found in chromosomes.
In mitochondria, DNA is found in the mitochondrial genome.
In viruses, DNA can be found in the viral genome.
RNA:
In the nucleus of cells, RNA is transcribed from DNA.
In the cytoplasm of cells, RNA is translated into proteins.
In ribosomes, RNA is used to assemble proteins.
In viruses, RNA can be found in the viral genome.
Eukaryote
Graphic representation of cell containing genetic material in cytoplasm
Prokaryote
Graphic representation of Prokaryote containing genetic material in cytoplasm
Virus Representation
Graphic representation of Virus with a capsid containing DNA
Types of Viral Genetic Material
Graphic representation of Viri with four examples of types genetic material
Nucleosome
Histones and nucleosomes play crucial roles in packaging and organizing DNA within the cell nucleus. Here's a summary of each:
Histones are a family of small, positively charged proteins found in eukaryotic cells. They are involved in compacting DNA into a more condensed and organized structure, known as chromatin, which is necessary for efficient storage and regulation of genetic information. Histones have a high affinity for the negatively charged phosphate groups on DNA molecules due to their positive charge. There are five main types of histones: H1, H2A, H2B, H3, and H4.
DNA wrapped around Histones
DNA wrapped around three Histone complexes
Nucleosome is the fundamental unit of chromatin structure. It consists of DNA wrapped around a core of eight histone proteins, forming a spherical structure. The core histone proteins include two copies each of H1, H2A, H2B, H3, and H4. The DNA wraps around the histone core in approximately 1.65 turns, resulting in a compacted structure. The linker DNA connects one nucleosome to the next, and a histone H1 molecule helps stabilize this organization.
The nucleosome serves several key functions:
Compaction: Nucleosomes compact long DNA molecules into a more manageable size, allowing them to fit within the limited space of the cell nucleus.
Regulation: The packaging of DNA into nucleosomes controls access to the genetic information. Certain regions of DNA may be tightly wound and less accessible, while others are more open and available for transcription.
Epigenetic Regulation: Chemical modifications of histones and DNA within nucleosomes can influence gene expression without altering the underlying DNA sequence. This is a crucial mechanism for regulating various cellular processes.
DNA Replication and Repair: Nucleosomes need to be temporarily disassembled during processes like DNA replication and repair to allow access to the DNA strand
In summary, histones are proteins that play a critical role in packaging and organizing DNA, and nucleosomes are the basic units of chromatin structure, formed by DNA wrapping around histone cores. This structural organization is essential for regulating gene expression, maintaining genome stability, and carrying out various cellular processes.
1AOI | Complex Between Nucleosome Core Particle (H2A, H2B, H3, and H4)
Did these objects with strands wrapped around them remind you of curling your hair? Do you smoke or vape? well if you do your basically preventing your body from accessing large volumes of genetic data, such as how to build skin, or breakdown compounds. Methylation should only be handled by your body, not by an external man-made compound. Those little things that look like worms eminating from the curling role? yeah that's where the substances you vape attach to. It's why vap girls are unattractive, why you can't start a family with a vape female or plan a future all they get are fuckboys.. Next section will be about cancers, and dyes. Why you should stop looking for products sold with food coloring. How dumb people buy food based on how it looks and not how it performs in your body, and ways to make any man love you, stay tuned.
I love melting people. Infernos are child's play, I want that plasma. I could build cities on plasma, reduce carbon emissions, cancers, radioactive material all gone. "Wait, is he talking about his fluid or what? Do I really need to stop vaping, it makes me feel like I'm holding something warm." -Hot girl. Just cause you hot don't make you attractive. Although plasma on the other hand is both. A substance pushed to the extent that is breaks into a dual state, both of which are highly damaging if not handled properly. First you got the electrons ripping apart anything that it touches, followed by the protons that drag you into a form you may not want. "Wait so I do need to stop vaping cause those red circles are his animosity toward me? I mean I was hungry I just thought it was going to melt me." -Hot girl. Little did she know I could of turned her into a fusion reactor.
Wondering why she prefers to hold something warm? We'll get to that in this chapter.
The Epigenetic Landscape: Chromatin Regulation
DNA is not free-floating; it is wrapped around histone octamers to form nucleosomes.
The accessibility of regulatory elements is controlled by the density of this packaging.
Use the slider below to simulate the transition from active Euchromatin to silenced Heterochromatin.
Open (Active)Closed (Silent)
StateEuchromatin
Histone MarkH3K4me3 / H3K27ac
TranscriptionPOSSIBLE
Nucleoside Analogs
Nucleoside analogues are molecules that resemble naturally occurring nucleosides.
Nucleoside analogs
Are molecules that are similar to natural nucleosides, but they have one or more modifications that make them less susceptible to degradation by cellular enzymes.
Can be used to inhibit the replication of viruses and cancer cells.
Work by being incorporated into DNA or RNA, where they can cause chain termination or other errors.
Are generally safe and well-tolerated, but they can have side effects such as nausea, vomiting, and diarrhea.
Are used to treat a variety of diseases, including HIV infection, hepatitis B and C, and cancer.
Nucleoside Analog
Graphic representation of
2-Aminopurine Nucleoside Analog
Graphic representation of
Nucleoside analogs
Are used in a variety of therapeutic drugs, including antiviral, anticancer, and anti-inflammatory agents.
Nucleoside analogues work by interfering with the replication of nucleic acids (DNA and RNA).
They can do this by:
Inhibiting DNA polymerase, the enzyme that is responsible for copying DNA.
Competing with naturally occurring nucleosides for incorporation into DNA or RNA.
Causing mutations in DNA, which can prevent the virus from replicating.
Nucleoside analogues are generally well-tolerated, but they can have side effects such as bone marrow suppression, liver damage, and pancreatitis.
They are an important class of drugs that have saved millions of lives.
Here are some examples of nucleoside analogues:
Acyclovir is used to treat herpes simplex virus (HSV) infections.
Gemcitabine is used to treat cancer.
Mercaptopurine is used to treat cancer and autoimmune diseases.
Anabolism of Purines and Pyrimidines
Purines and pyrimidines are two types of nitrogenous bases that are essential building blocks of nucleotides, the monomers that make up DNA and RNA. The biosynthesis of purines and pyrimidines involves a series of enzymatic reactions that occur in different cellular compartments.
Anabolism and Catabolism of Nucleic Acid
GRAPHIC
The synthesis of purines begins with the formation of phosphoribosylamine from PRPP (5-phosphoribosyl-1-pyrophosphate) and glutamine, catalyzed by the enzyme glutamine phosphoribosyl amidotransferase (GPAT).
Phosphoribosylamine is then converted into inosine monophosphate (IMP) via a series of enzymatic reactions. IMP is a precursor for the synthesis of all other purine nucleotides.
IMP can be converted into adenosine monophosphate (AMP) or guanosine monophosphate (GMP) through different pathways. The synthesis of AMP involves the addition of an amino group from aspartate to IMP, while the synthesis of GMP involves the addition of a nitrogen-containing group from glutamine to IMP.
Once AMP and GMP are synthesized, they can be further phosphorylated to form ADP and GDP, respectively, which are then used to synthesize ATP and GTP, important energy molecules in the cell.
Pyrimidine biosynthesis begins with the synthesis of carbamoyl phosphate from bicarbonate, ATP, and glutamine, catalyzed by the enzyme carbamoyl phosphate synthetase II (CPS II).
Carbamoyl phosphate is then combined with aspartate to form dihydroorotate, catalyzed by the enzyme dihydroorotase.
Dihydroorotate is then converted into orotate by the enzyme dihydroorotate dehydrogenase.
Orotate is then converted into uridine monophosphate (UMP) via a series of enzymatic reactions. UMP is a precursor for the synthesis of all other pyrimidine nucleotides.
UMP can be converted into cytidine monophosphate (CMP) or thymidine monophosphate (TMP) through different pathways. The synthesis of CMP involves the addition of a nitrogen-containing group from glutamine to UMP, while the synthesis of TMP involves the addition of a methyl group from tetrahydrofolate to UMP.
Once CMP and TMP are synthesized, they can be further phosphorylated to form CDP and TDP, respectively, which are then used to synthesize CTP and dTTP, important nucleotides used in DNA synthesis.
Overall, the biosynthesis of purines and pyrimidines is an important process that provides the necessary building blocks for DNA and RNA synthesis, as well as for the production of energy molecules in the cell.
Fermentation of Alcohol (Ethanol)
GRAPHIC
Fermentation of Alcohol (Ethanol)
GRAPHIC
Summary |
Fermentation of Alcohol (Ethanol)
GRAPHIC
Fermentation of Alcohol (Ethanol)
GRAPHIC
Purines and Pyrimidine Catabolism
Purine and pyrimidine nucleotides can undergo catabolism to produce free bases, ribose-1-phosphate, and ammonia. The catabolism pathways for purines and pyrimidines are different and are described below
Catabolism of Purine Nucleotides:
Deamination: The first step in the catabolism of purine nucleotides is the removal of the amino group from the purine ring. This process is called deamination, and it is catalyzed by enzymes called deaminases. The result of deamination is the formation of a purine base (hypoxanthine or guanine), ammonia, and carbon dioxide.
Phosphorolysis: The purine base is then cleaved from the ribose sugar by a process called phosphorolysis, which is catalyzed by enzymes called nucleoside phosphorylases. This results in the formation of ribose-1-phosphate and the free purine base (hypoxanthine or guanine).
Conversion of Hypoxanthine to Xanthine and Uric Acid: Hypoxanthine is converted to xanthine by the enzyme xanthine oxidase. Xanthine is then converted to uric acid by the same enzyme. Uric acid is a waste product that is excreted in the urine.
Catabolism of Pyrimidine Nucleotides:
Deamination: The first step in the catabolism of pyrimidine nucleotides is the removal of the amino group from the pyrimidine ring. This process is called deamination, and it is catalyzed by enzymes called deaminases. The result of deamination is the formation of a pyrimidine base (uracil or thymine), ammonia, and carbon dioxide.
Hydrolysis: The pyrimidine base is then cleaved from the ribose sugar by a process called hydrolysis, which is catalyzed by enzymes called nucleoside hydrolases. This results in the formation of ribose-1-phosphate and the free pyrimidine base (uracil or thymine).
Conversion of Uracil to β-Alanine: Uracil is converted to β-alanine by the sequential action of four enzymes: dihydropyrimidine dehydrogenase, dihydropyrimidinase, β-ureidopropionase, and β-alanine transaminase.
Conversion of Thymine to β-Amino Isobutyrate: Thymine is converted to β-amino isobutyrate by the sequential action of three enzymes: thymine dioxygenase, 5,6-dihydrouracil hydratase, and N-carbamyl-β-alanine synthase.
Overall, the catabolism of purine and pyrimidine nucleotides is important for maintaining nucleotide balance in the cell and for the disposal of excess nucleotides.
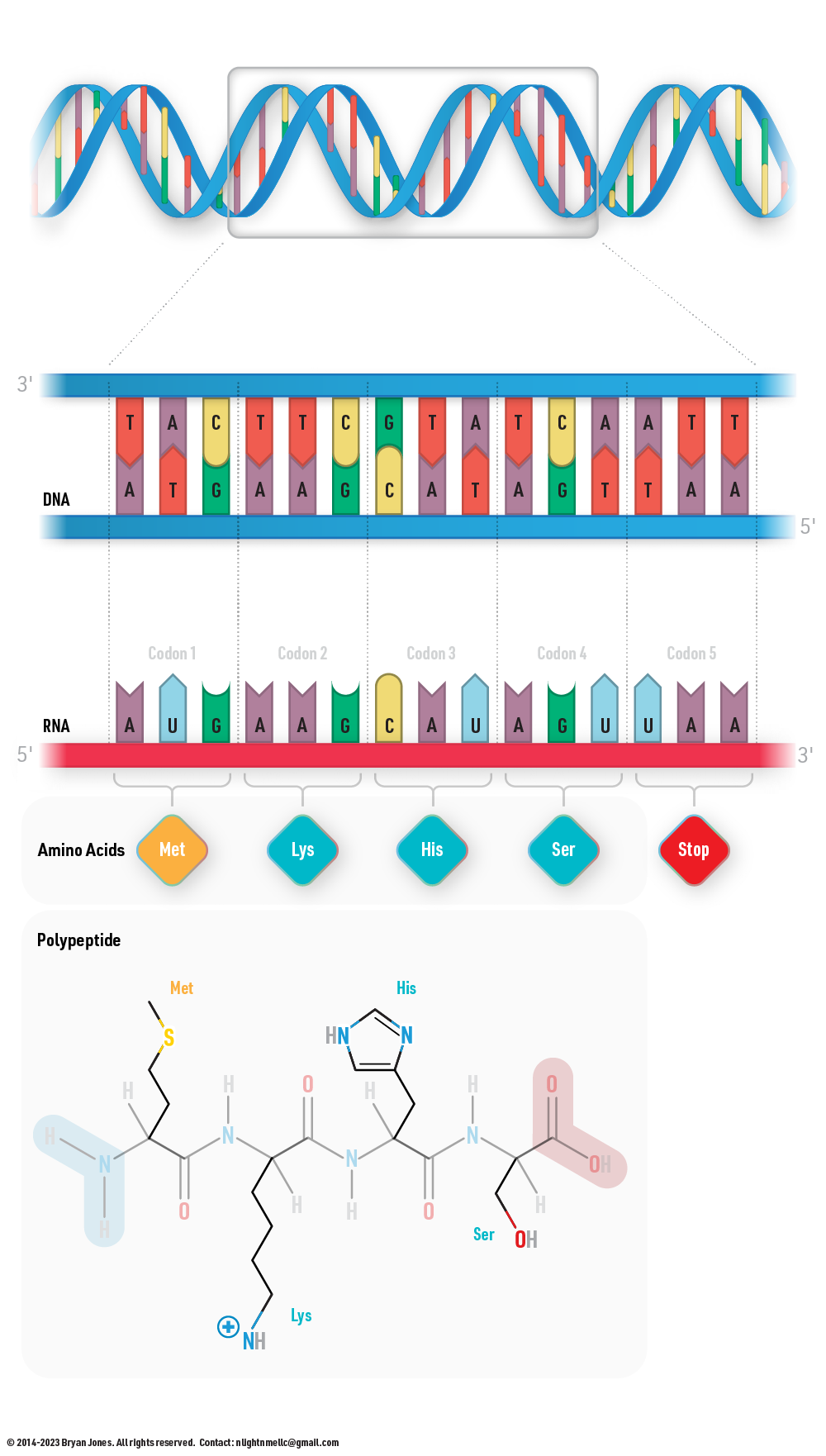
Nucleic Acids as Information Storage
The basic structure of nucleic acids is composed of nucleotides, which are linked together by phosphodiester bonds. Each nucleotide contains a sugar molecule, either deoxyribose in DNA or ribose in RNA, a phosphate group, and a nitrogenous base. The nitrogenous bases in DNA are adenine, thymine, cytosine, and guanine, while in RNA, uracil replaces thymine. The arrangement of these nitrogenous bases forms the genetic code that determines the traits and characteristics of an organism.
DNA replication
DNA replication is the process by which a cell makes an exact copy of its DNA before cell division. This ensures that each daughter cell receives a complete set of genetic information. The process of DNA replication involves the unwinding of the double helix, separation of the two strands, and the synthesis of new complementary strands by adding nucleotides. DNA replication is a highly accurate process, with an error rate of less than one mistake per billion nucleotides replicated.
Transcription
Transcription is the process by which the genetic information stored in DNA is used to produce RNA molecules. The first step in transcription is the unwinding of the double helix, followed by the binding of RNA polymerase to the DNA template strand. The RNA polymerase then moves along the template strand, synthesizing a complementary RNA strand using the nitrogenous base pairing rules (adenine with uracil, cytosine with guanine). Transcription is a critical step in gene expression and regulation.
Translation
Translation is the process by which the genetic information stored in mRNA is used to produce proteins. The process of translation takes place in the ribosome, where the mRNA is read by transfer RNA (tRNA) molecules that carry specific amino acids. The tRNA molecules bind to the codons (three nitrogenous bases) on the mRNA using complementary base pairing rules. The amino acids carried by the tRNA molecules are then linked together in a specific order to form a polypeptide chain, which will ultimately fold into a functional protein.
Understanding the processes of DNA replication, transcription, and translation is essential to understanding how genetic information is transferred and used in living organisms. These processes are complex and highly regulated, and they play a critical role in the development, growth, and functioning of all living organisms.
Hybrid Information Systems
Nucleic acid ratio's dictate the function of the information molecule and likely underwent numerous paradigm shifts before reaching it's current state. Life likely emerged from a co-evolutionary dance where RNA and Peptides stabilized each other's metabolic and structural constraints.
Adenine (A)20%
Thymine (T)20%
Cytosine (C)20%
Guanine (G)20%
Uracil (U) - RNA Activity20%
DNA Replication
DNA replication is the process by which a cell makes an exact copy of its DNA before cell division. This ensures that each daughter cell receives a complete set of genetic information.
The process of DNA replication involves the unwinding of the double helix, separation of the two strands, and the synthesis of new complementary strands by adding nucleotides. DNA replication is a highly accurate process, with an error rate of less than one mistake per billion nucleotides replicated.
1 | The two strands of the double helix are unwound
The two strands of the double helix are unwound
2 | The unwound DNA is separated by helicase.
The unwound DNA is separated by helicase.
3 | DNA polymerase proceeds along the DNA molecule, attaching the correct nucleotides according to the pattern of the template.
DNA polymerase proceeds along the DNA molecule, attaching the correct nucleotides according to the pattern of the template.
4 | The new DNA contains one strand of the newly synthesized DNA and the original
template strand.
The new DNA contains one strand of the newly synthesized DNA and the original template
strand.
Bidirectional Replication Dynamics
Macroscopic Supercoiling & Topological Stress
Parental Template
CMG Helicase
Leading Strand (5'→3')
Pol ε (Leading)
Lagging Strand (Okazaki)
Topoisomerase
Replication
Semi conservative replication of DNA
Topological Tension
Supercoiling: Twist vs. Writhe
FormulaΔLk = ΔTw + ΔWr
RSC / SWI-SNF Remodeler
Supercoiling Management by DNA Gyrase: DNA gyrase (DNA topoisomerase II) acts to relieve supercoiling tension by introducing negative supercoils ahead of the replication fork, ensuring smooth unwinding of the DNA during replication in prokaryotic cells like bacteria.
Unwinding of DNA: DNA replication begins when an enzyme called helicase unwinds the double-stranded DNA
molecule at the origin of replication. Helicase breaks the hydrogen bonds between the complementary base
pairs (A-T and G-C), causing the two DNA strands to separate and form a Y-shaped structure known as the
replication fork.
Formation of Single-Stranded DNA Templates: As the DNA strands separate, each strand serves as a template for
the synthesis of a new complementary strand. The two single-stranded DNA templates are oriented in opposite
directions because DNA is antiparallel, meaning one strand runs in the 5' to 3' direction while the other
runs in the 3' to 5' direction.
Stabilization of Unwound DNA: After the DNA helicase unwinds the double-stranded DNA, single-stranded DNA
tends to re-anneal or form secondary structures. To prevent this and stabilize the unwound parental DNA,
specific proteins called single-stranded DNA-binding proteins (SSBs) bind to the exposed single-stranded DNA
regions. SSBs coat the single-stranded DNA, preventing it from re-forming double-stranded regions and
protecting it from degradation.
RNA Primers: DNA polymerases require a starting point to initiate DNA synthesis. Primase is an enzyme that
synthesizes short RNA primers complementary to the DNA templates. These primers provide the 3' end necessary
for DNA polymerase to add nucleotides.
DNA Synthesis and Elongation: DNA polymerase extends the RNA primers by adding complementary
deoxyribonucleotides (dNTPs) to the growing DNA strand. The leading strand is synthesized continuously,
while the lagging strand is synthesized in a series of short segments.
DNA Polymerase: At the replication fork, DNA polymerase enzymes play a crucial role in the synthesis of new
DNA strands. DNA polymerases add complementary nucleotides to the exposed single-stranded templates. There
are two main types of DNA polymerases involved in DNA replication: the leading strand polymerase and the
lagging strand polymerase.
Leading Strand: The leading strand is synthesized continuously in the 5' to 3' direction because its
template strand is oriented in the 3' to 5' direction. DNA polymerase can add nucleotides
continuously in this direction.
Lagging Strand: The lagging strand is synthesized discontinuously in short fragments called Okazaki
fragments. This is because its template strand is oriented in the 5' to 3' direction, which means
DNA polymerase must synthesize the new strand in the opposite direction. RNA primers are initially
synthesized on the lagging strand to provide a starting point for DNA synthesis, and then DNA
polymerase synthesizes short fragments of DNA, which are later joined together by another enzyme
called DNA ligase.
DNA Ligase: After the RNA primers on the lagging strand are replaced with DNA, there are small gaps between
the Okazaki fragments. DNA ligase joins these fragments together by forming phosphodiester bonds, creating a
continuous strand of DNA.
Replication Progression: The replication fork progresses along the DNA molecule, continually unwinding and
synthesizing new strands until the entire DNA molecule is replicated.
Activity at Replication Fork
Graphic Representation of DNA seperating at replication fork while multiple types of enzymes, cut, duplicate, and repair DNA strands
Replication Fork
Graphic Representation of DNA seperating at replication fork while multiple types of enzymes, cut, duplicate, and repair DNA strands
Replisome Coordinator
S-Phase Chromatin Restructuring
Parental Histone
DNA Primase
Nascent Histone
DNA Ligase
Leading Strand
SSB (RPA)
Okazaki Fragment
FACT Chaperone
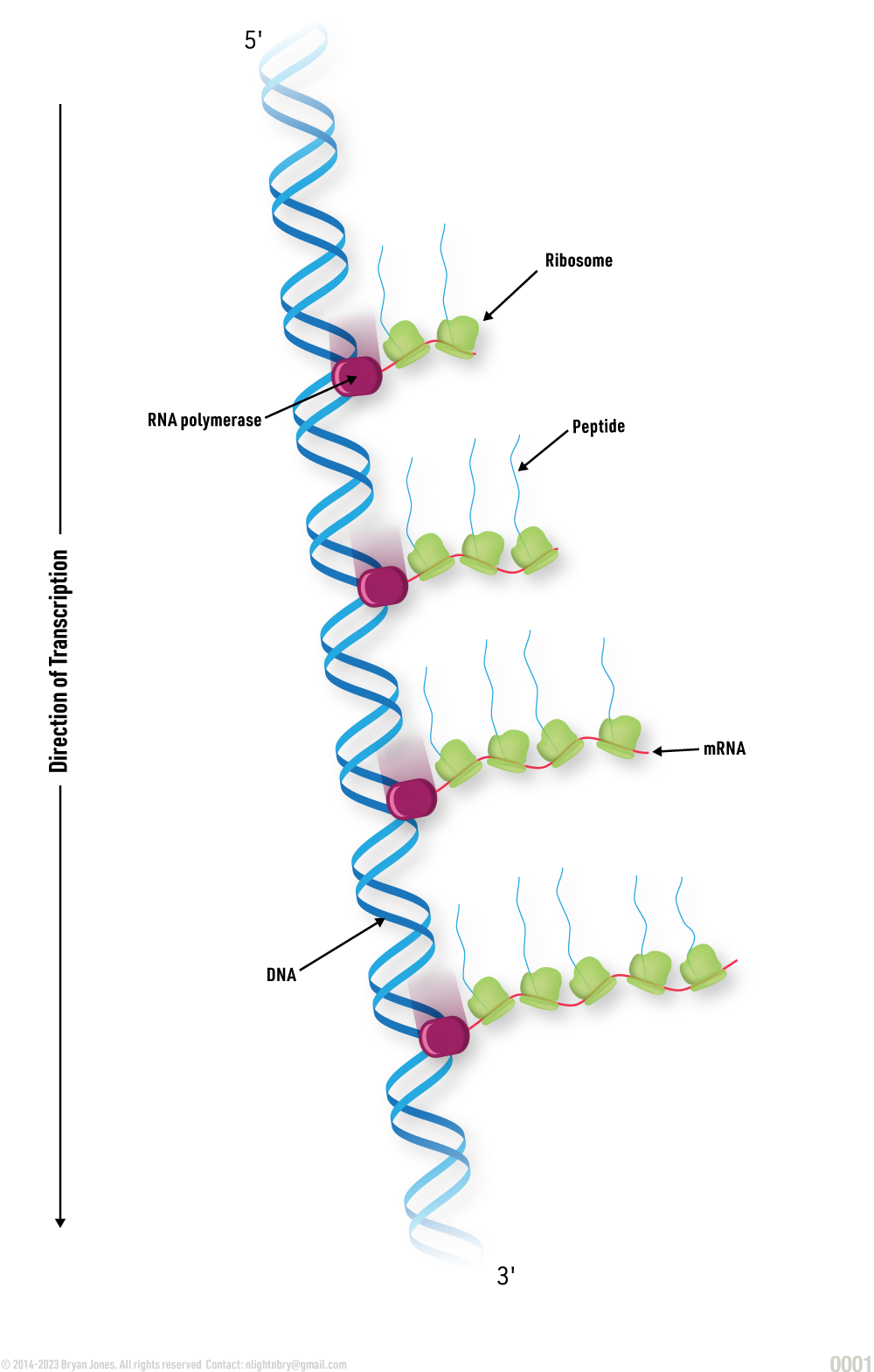
mRNA Transcription
mRNA is synthesized from DNA in a process called transcription. mRNA is then translated into proteins, which are the building blocks of life.
Transcription is the process of copying a section of DNA into mRNA. This process is catalyzed by an enzyme called RNA polymerase.
Translation is the process of converting mRNA into proteins. This process is catalyzed by ribosomes.
Overview of stages
Initiation
Elongation
Termination
Processing
Translation
Explanation of each stage of transcription:
1 |Initiation: The first step in transcription is the binding of RNA polymerase to a promoter sequence on the DNA. The promoter sequence is a specific sequence of nucleotides that tells RNA polymerase where to start transcribing.
Initiation
transcription: Initiation
2 |Elongation: Once RNA polymerase is bound to the promoter sequence, it begins to move along the DNA, adding nucleotides to the RNA molecule one by one. The nucleotides are added in the order that they are found in the DNA, so the RNA molecule is complementary to the DNA sequence.
Elongation
transcription: Elongation
3 |Termination: RNA polymerase continues to elongate the RNA molecule until it reaches a termination sequence on the DNA. The termination sequence is a specific sequence of nucleotides that tells RNA polymerase to stop transcribing.
Termination
transcription: Termination
RNA and RNA Polymerase are released, and the DNA double helix reforms.
Helix reforms
Helix reforms
4 |Processing: After transcription is complete, the RNA molecule is processed. This may include adding a 5' cap and a 3' poly-A tail. The 5' cap is a group of nucleotides that is added to the beginning of the RNA molecule. The 3' poly-A tail is a long chain of adenine nucleotides that is added to the end of the RNA molecule.
mRNA Synthesis Steps
GRAPHIC
5 |Translation: The processed RNA molecule is then translated into protein. Translation is the process of converting the RNA sequence into a protein sequence. This process is catalyzed by ribosomes.
Simultaneous Transcription and Translation
GRAPHIC
DNA > RNA > Protein
GRAPHIC
Transcription is the process of copying a gene's DNA sequence into an RNA molecule.
RNA polymerase is the enzyme that catalyzes transcription.
Transcription occurs in three stages: initiation, elongation, and termination.
During initiation, RNA polymerase binds to a promoter sequence on the DNA.
During elongation, RNA polymerase moves along the DNA, adding nucleotides to the RNA molecule one by one.
During termination, RNA polymerase reaches a termination sequence on the DNA and releases the RNA molecule.
The RNA molecule is then processed, which may include adding a 5' cap and a 3' poly-A tail.
The processed RNA molecule is then translated into protein.
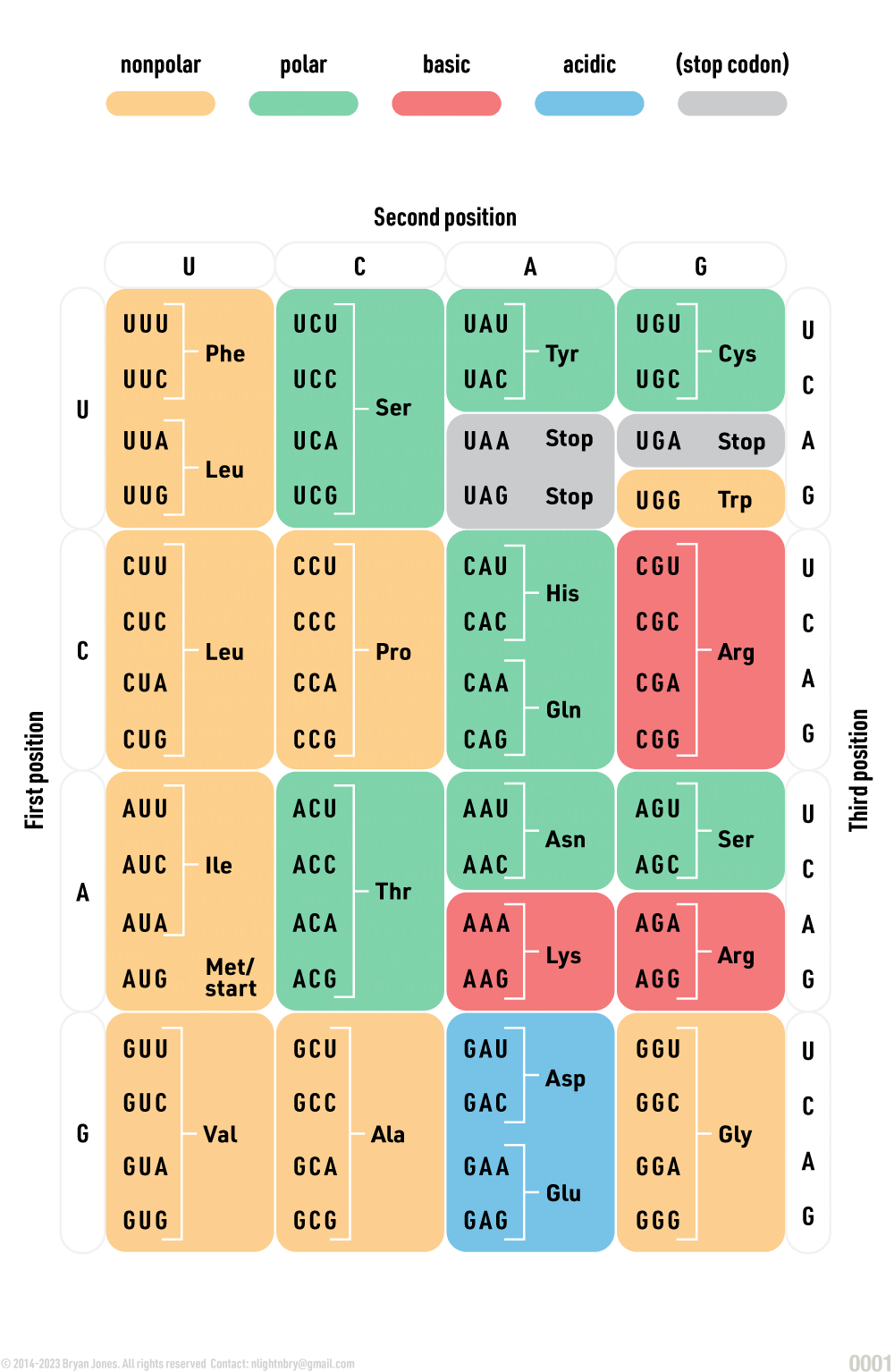
Genetic Code Table
The genetic code is a set of rules that specifies how DNA is translated into proteins.
The genetic code is universal, meaning that it is the same for all living organisms.
There are 64 codons, each of which codes for one of 20 amino acids.
Three codons (UAA, UAG, and UGA) are stop codons, which signal the end of a protein.
The genetic code is read in groups of three nucleotides, called codons.
Each codon corresponds to a specific amino acid or stop signal.
Genetic code, with the codons and their corresponding amino acids:
GRAPHIC
Transcription and Translation
DNA to RNA, RNA to Protein
Mutation
Mutation, not as random as you may think.
There are several types of mutations:
Point mutation: This type of mutation involves a single nucleotide substitution, deletion, or insertion.
Frameshift mutation: This type of mutation results from the insertion or deletion of one or more nucleotides that disrupts the reading frame of the gene.
Chromosomal mutation: This type of mutation involves changes in the structure or number of chromosomes, such as deletion, duplication, inversion, or translocation.
Silent mutation: This type of mutation does not result in any change in the amino acid sequence of the protein because it involves a nucleotide substitution that does not alter the codon.
Missense mutation: This type of mutation results in a change in the amino acid sequence of the protein due to a nucleotide substitution that alters the codon.
Nonsense mutation: This type of mutation results in a premature stop codon that truncates the protein.
Splice site mutation: This type of mutation involves a change in the consensus sequences at the splice sites that affect the splicing of pre-mRNA into mature mRNA.
Repeat expansion mutation: This type of mutation involves the expansion of short tandem repeats (STRs) in the DNA that can cause various genetic diseases.
Mutation Types
Normal
Normal
Frameshift Mutation
Frameshift Mutation
Missense Mutation
Missense Mutation
Nonsense Mutation
Nonsense Mutation
The bond length and bond angle of each nucleic acid (ATGC and U) can affect the stability of the molecule and its susceptibility to mutations.
For example, the bond between the nitrogen atom in guanine and the hydrogen atom in cytosine is weaker than the bond between the oxygen atom in adenine and the hydrogen atom in thymine. This means that the G-C base pair is more likely to break and be replaced by a different base pair, resulting in a mutation.
Why do different nucleic acids have different bond lengths and bond angles?
The bond lengths and bond angles of a molecule are determined by the hybridization of the atoms involved in the bond. Hybridization is the process of mixing atomic orbitals to create new orbitals that are better suited for bonding. The most common types of hybridization are sp3, sp2, and sp.
sp3 hybridization: This type of hybridization results in a tetrahedral geometry, with bond angles of approximately 109.5 degrees.
sp2 hybridization: This type of hybridization results in a trigonal planar geometry, with bond angles of approximately 120 degrees.
sp hybridization: This type of hybridization results in a linear geometry, with bond angles of approximately 180 degrees.
The nitrogen and oxygen atoms in nucleic acids are sp2 hybridized. This means that they have three bond orbitals and one lone pair orbital. The bond orbitals are used to form bonds with the carbon atoms in the sugar and phosphate groups, as well as with the hydrogen atoms in hydrogen bonds. The lone pair orbital is responsible for the repulsion between neighboring nitrogen and oxygen atoms, which helps to keep the DNA double helix stable.
How do bond lengths and bond angles affect mutation rates?
The bond length and bond angle of a molecule can affect its stability in two ways:
Hindrance: Steric hindrance is the repulsion between atoms that are too close together. If the bond length between two atoms is too short, the atoms will experience steric hindrance and the molecule will be less stable.
Bond strength: The strength of a bond is determined by the overlap between the atomic orbitals involved in the bond. If the bond angle between two atoms is not ideal, the overlap between the atomic orbitals will be less and the bond will be weaker. A weaker bond is more likely to break, so nucleic acids with weaker bonds are more susceptible to mutations. For example, the G-C base pair has a weaker bond than the A-T base pair, so G-C base pairs are more likely to mutate.
Conclusion:
The bond length and bond angle of each nucleic acid can affect the stability of the molecule and its susceptibility to mutations. Nucleic acids with weaker bonds are more likely to mutate, and mutations in nucleic acids can cause a variety of diseases.
Repairing Mutation
DNA mutation can be repaired in many ways, here is one.
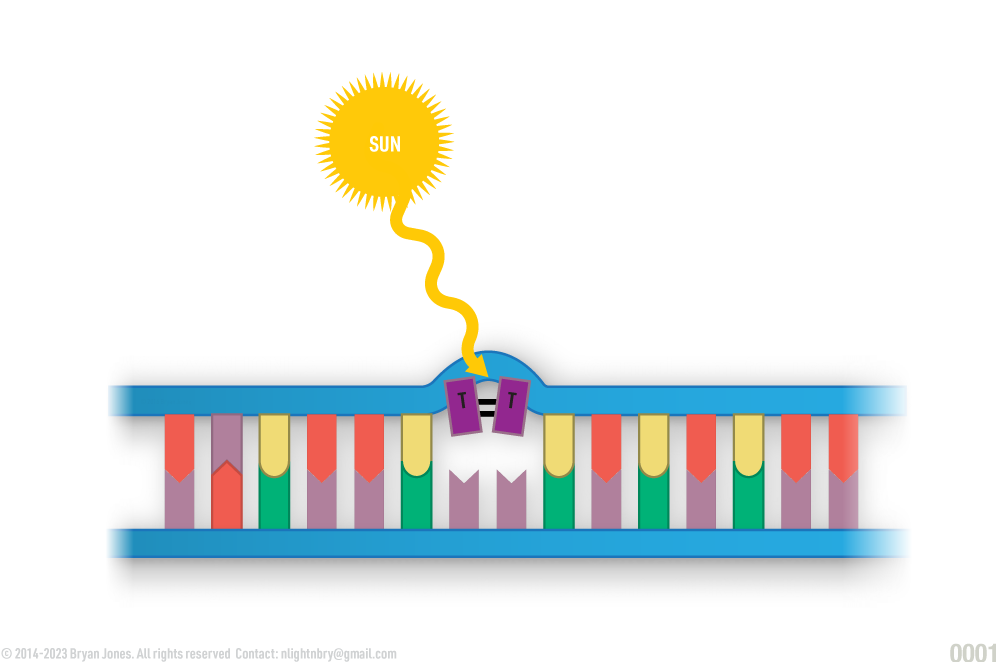
Thymine-Dimer Mutation
DNA healthy before representational Thymine Dimer Mutation
1 | Mutations can occur due to UV radiation, for example, if DNA is submerged into a solution and then Ionized with UV it can cause changes in structure. Remember the basics, if you apply energy to something it's electron configuration changes.
Step 1
representational DNA damaged by Ultra-violet
2 | Structural changes along the phosphate-deoxyribose backbone of DNA get's detected by various mechanisms of which are not shown. An enzyme is essentially pulled to the location of damage to begin excision.
Step 2
Structural changes along the phosphate-deoxyribose backbone of DNA get's detected by various mechanisms of which are not shown. An enzyme is essentially pulled to the location of damage to begin excision.
3 | Photolyase excesses the Thymine-Dimer from DNA strand.
Photolyase is a direct repair enzyme that uses light energy to break the bonds of the thymine dimer. It is found in most organisms, but not in placental mammals such as humans.
Nucleotide excision repair is an indirect repair enzyme that removes the thymine dimer and then fills in the gap with new nucleotides. It is the primary repair mechanism for thymine dimers in humans.
Step 3
Photolyase excesses the Thymine-Dimer from DNA strand.
4 | DNA polymerase travels along strand like a Maglev train filling in the missing nucleotides one-by-one.
Step 4
DNA polymerase travels along strand like a Maglev train filling in the missing nucleotides one-by-one.
5 | DNA Ligase joins the strand's phosphate-deoxyribose backbone
Step 5
DNA Ligase joins the strand's phosphate-deoxyribose backbone
6 | DNA Ligase returns to the surrounding substance called nucleoplasm which is found inside the nucleus. Nucleoplasm is a gel-like substance that contains the nucleus's DNA, RNA, and proteins. It is also home to the nucleolus, which is a structure that produces ribosomes.
Step 6
DNA Ligase returns to the surrounding substance called nucleoplasm which is found inside the nucleus.
Aptamers
Aptamers are single-stranded nucleic acid molecules that can bind to specific target molecules with high affinity and specificity. Aptamers are similar to antibodies, but they are easier to produce, more stable, and less immunogenic. Aptamers have many potential applications in diagnostics, therapeutics, and biotechnology.
Aptamers are short, single-stranded DNA or RNA molecules that are able to bind to specific target molecules, such as proteins, small molecules, or even cells. They are designed to recognize and bind to their targets with high specificity and affinity, similar to how antibodies work.
What makes aptamers unique is that they can be synthesized chemically, which means that they can be customized to recognize virtually any target molecule. They are also relatively easy to modify, allowing researchers to optimize their binding properties or add additional functionality.
One potential application of aptamers is in diagnostics, where they can be used to detect specific biomarkers or other molecules associated with disease. They can also be used as therapeutics, either by inhibiting the activity of a target molecule or by delivering drugs or other agents directly to specific cells or tissues.
Aptamers are a promising tool in medicine and biomedical research, with many potential applications in diagnosis, therapy, and drug discovery.
Aptamers are short, single-stranded DNA or RNA molecules that are typically between 20 to 100 nucleotides in length. They are designed to bind specifically and tightly to a target molecule, such as a protein, small molecule, or even a whole cell. Aptamers are created through a process called Systematic Evolution of Ligands by EXponential enrichment (SELEX), which involves repeatedly selecting the aptamers that bind most strongly to the target from a large library of random DNA or RNA sequences.
Aptamers have several advantages over traditional protein-based affinity reagents such as antibodies. Firstly, they can be selected against targets that are difficult to produce in large quantities, toxic, or that have a short half-life. Secondly, aptamers can be easily modified with various functional groups, such as fluorophores, to allow for detection or imaging of the target molecule. Thirdly, aptamers are often more stable than antibodies and can be stored at room temperature for long periods.
Aptamers have a wide range of applications in biomedical research and medicine. They can be used as diagnostic tools to detect the presence of disease biomarkers in patient samples with high sensitivity and specificity. They can also be used as therapeutics to modulate the activity of specific proteins or cells in disease treatment. Additionally, aptamers can be used as tools for targeted drug delivery, as they can be conjugated with drugs or other molecules to deliver them specifically to diseased cells or tissues.
Aptamers are a powerful class of affinity reagents that have a wide range of applications in biomedical research and medicine. Their flexibility, specificity, and stability make them promising candidates for a variety of diagnostic, therapeutic, and drug delivery applications.
Gene Structure
A gene is composed of several components that work together to encode the information necessary to produce a functional protein. The structure of a gene can be divided into several key components, each with its own unique function
The function of each of these components is essential for the proper expression of genes. The promoter and transcription start site initiate the process of transcription, while the coding region encodes the information necessary to produce a functional protein. The terminator signals the end of transcription, and regulatory regions help to control the expression of the gene. The polyadenylation signal and the poly(A) tail are involved in mRNA processing and export, while the 5' cap is involved in the initiation of translation. Together, these components work to ensure that genes are expressed in the proper place, at the proper time, and in the proper amount, allowing for the production of the proteins necessary for proper cellular function.
Difference between Prokaryotic and Eukaryotic Transcription
: Coding regions comprised of Exons and Introns
Prokaryotic: Coding regions comprised of Exons.
Gene Architecture
Promoter: The promoter is a regulatory sequence located near the beginning of the gene. It is responsible for initiating the transcription of the gene by binding to RNA polymerase, the enzyme responsible for synthesizing RNA from DNA.
Transcription Start Site: The transcription start site is the specific location on the DNA where transcription begins. It is typically located near the promoter.
Coding Region: The coding region of a gene is the portion of the gene that encodes the information necessary to produce a functional protein. It is composed of exons, which are the coding sequences, and introns, which are the non-coding sequences that are removed during mRNA processing.
Terminator: The terminator is a sequence located at the end of the gene that signals the end of transcription.
Regulatory Regions: Regulatory regions are sequences located throughout the gene that help to control its expression. These regions can act as enhancers, which increase gene expression, or as silencers, which decrease gene expression.
Polyadenylation Signal: The polyadenylation signal is a sequence located at the end of the gene that signals the addition of a poly(A) tail to the mRNA molecule during processing.
Poly(A) Tail: The poly(A) tail is a string of adenine nucleotides added to the 3' end of the mRNA molecule during processing. It helps to stabilize the mRNA and is involved in the export of the mRNA from the nucleus to the cytoplasm.
5' Cap: The 5' cap is a modified guanine nucleotide added to the 5' end of the mRNA molecule during processing. It helps to stabilize the mRNA and is involved in the initiation of translation.
Eukaryote Transcription Summary
Eukaryote Transcription Summary
Learn More | Gene Architecture
Transposons
Transposons are genetic elements that can move from one location to another within the genome.
A transposable element (TE), also known as a jumping gene, is a DNA sequence that can change its position within the genome of a cell or organism. Transposons are found in all domains of life, from bacteria to humans. They are often referred to as "selfish DNA" because they do not appear to serve any essential function for the organism, but instead only copy and amplify themselves.
Gene Transposons
GRAPHIC
There are two main types of transposons:
Two main types of transposons: DNA transposons and retrotransposons. DNA transposons move by a "cut-and-paste" mechanism, in which they are excised from one location in the genome and then inserted into another location. Retrotransposons move by a "copy-and-paste" mechanism, in which they are first transcribed into RNA and then reverse transcribed back into DNA.
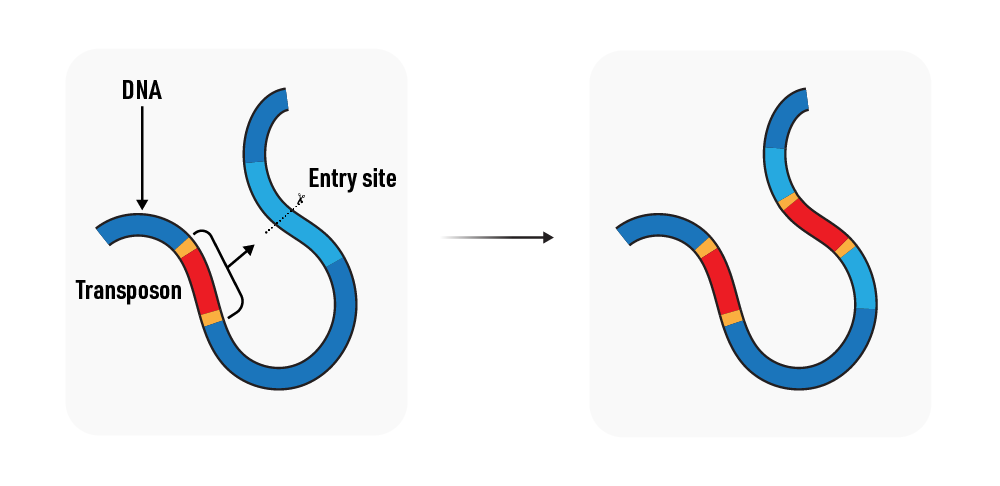
1 | DNA transposons: Also called “class 2” transposons, DNA transposons use a “cut-and-paste” mechanism to move within the genome. They encode their own transposase enzyme, which recognizes specific sequences at the ends of the transposon and catalyzes the excision and reintegration of the transposon at a new location in the genome.
DNA transposons
Finally, the transposon may jump to a plasmid
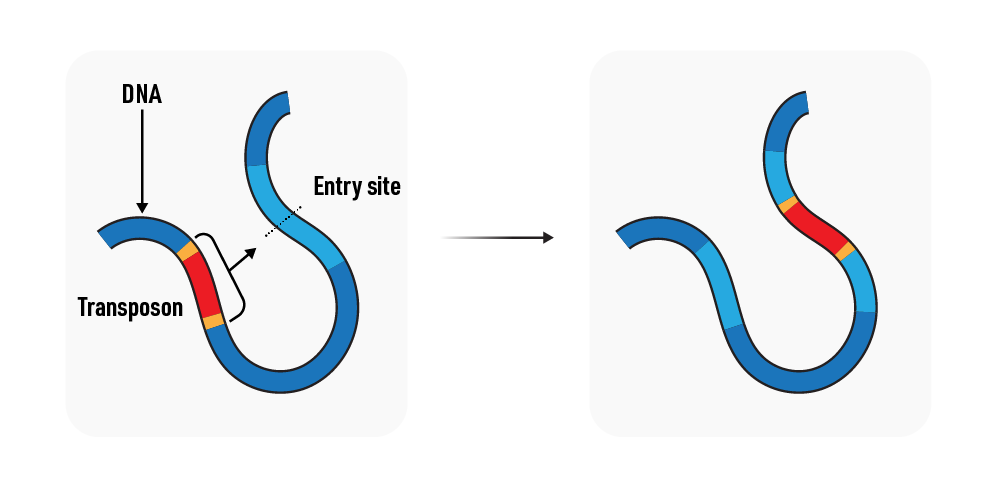
2 | Retrotransposons: Also called “class 1” transposons, retrotransposons use a “copy-and-paste” mechanism to move within the genome. Retrotransposons are transcribed into RNA by the host cell, and the RNA is reverse transcribed into DNA by the retrotransposon-encoded reverse transcriptase enzyme. The resulting DNA copy is then integrated into a new location in the genome. Retrotransposons can be further divided into two subclasses based on the presence or absence of long terminal repeats (LTRs): LTR retrotransposons and non-LTR retrotransposons.
Retrotransposons
Finally, the transposon may jump to a plasmid
Transposon transfer options
The transposon may excise itself and move from one location to another in the genome, maintaining itself at a single copy per cell.
The transposon may also replicate prior to moving, leading to an increase in the copy number and a greater effect on the genome of the host.
Finally, the transposon may jump to a plasmid, which can then be transferred to another bacterial cell.
Transposon transfer options
Finally, the transposon may jump to a plasmid
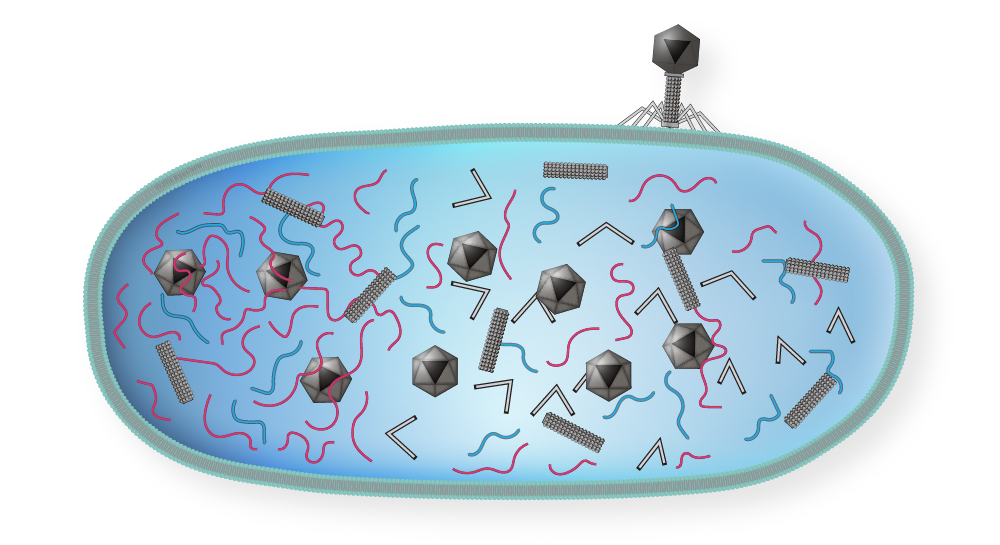
Transduction
Transduction is a process by which a bacteriophage transfers bacterial DNA from one host cell to another. There is two types of transduction, generalized and specialized.
Specialized Transduction
In specialized transduction, bacteriophages transfer specific genes located near the prophage integration site when the prophage excises from the bacterial chromosome.
The transferred DNA usually consists of a limited set of bacterial genes located near the integration site.
It leads to the transfer of a select group of bacterial genes.
The recipient cell typically gains genes that are functionally related and may be useful.
Specialized transduction is associated with bacteriophages that have integrated their DNA into the host chromosome (prophages).
Generalized Transduction
In generalized transduction, bacteriophages randomly package and transfer any fragment of bacterial DNA during the lytic cycle.
The transferred DNA can include both non-essential and essential genes for the bacterial cell.
It can lead to the transfer of a wide range of bacterial genes.
The recipient cell may gain new genetic material but can also receive essential genes that may not be useful.
Generalized transduction is more common in bacteriophages that do not integrate their DNA into the host chromosome.
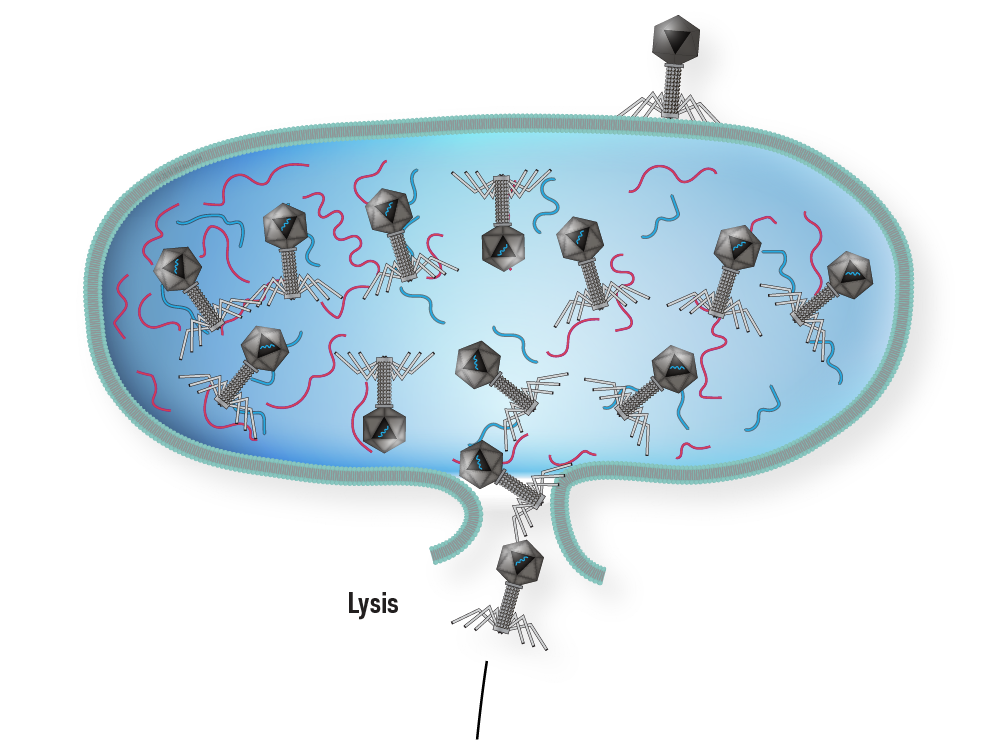
Adsorption: The bacteriophage attaches to the surface of a susceptible host bacterial cell and injects its DNA into the cell.
Replication and synthesis of phage DNA and proteins: The injected phage DNA takes control of the host cell's machinery and directs the synthesis of new phage DNA and proteins.
Packaging of phage DNA: During this stage, phage DNA is packaged into new phage particles.
Lytic cycle: Once enough phage particles have been assembled, they lyse (burst open) the host cell, releasing the newly synthesized phage particles.
Mistaken packaging of bacterial DNA: Occasionally, during the packaging process, a piece of bacterial DNA gets mistakenly packaged into a phage particle.
Infection of a new host cell: When the transducing phage particle infects a new host cell, it injects the bacterial DNA into the cell along with its own DNA.
Incorporation of bacterial DNA into the host genome: The bacterial DNA is integrated into the host cell's genome through recombination events.
Selection of transductants: Some of the new host cells will have acquired a new gene from the transducing phage particle, and these cells can be selected for by growing them in a selective medium that requires the new gene product for growth.
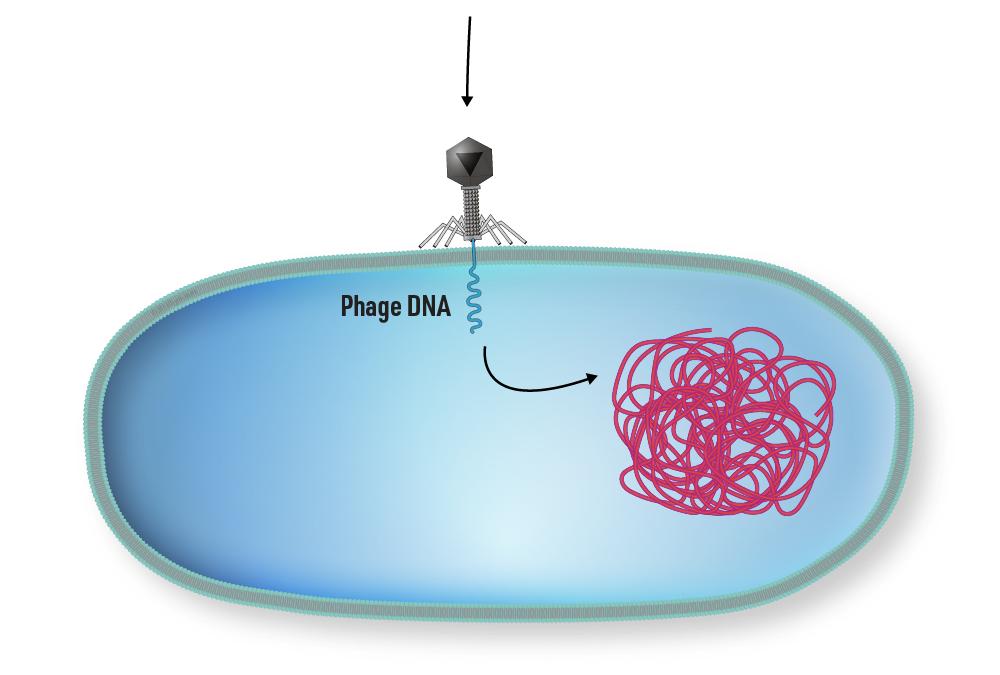
1 | A phage infects cell A by attaching to the cell’s plasma membrane.
Step 1
Generalized Transduction step 1
2 | Replication begins, phage DNA and proteins are made.
Step 2
Generalized Transduction step 2
3 | The bacterial chromosome is broken into pieces.
Step 3
Generalized Transduction step 3
4 | Assembly of phage components begins.
Step 4
Generalized Transduction step 4
5 | Phages are fully assembled and DNA is packaged in a phage capsid. Occasionally during phage assembly pieces of bacterial DNA are packaged in a phage capsid.
Step 5
Generalized Transduction step 5
6 | The cell lyses and releases the mature phages, including the genetically altered one.
Step 6
Generalized Transduction step 6
7 | A phage carrying bacterial DNA infects a new host cell by injecting the DNA from cell A instead of the viral nucleic acid.
Step 7
Generalized Transduction step 7
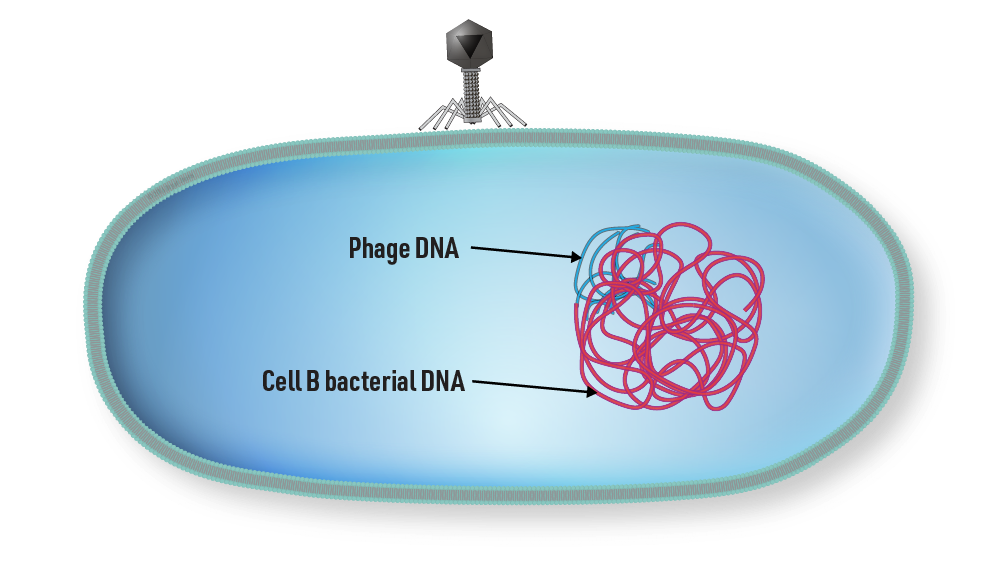
8 | Cell B receives the DNA and incorporates it into its own DNA.
Step 8
Generalized Transduction step 8
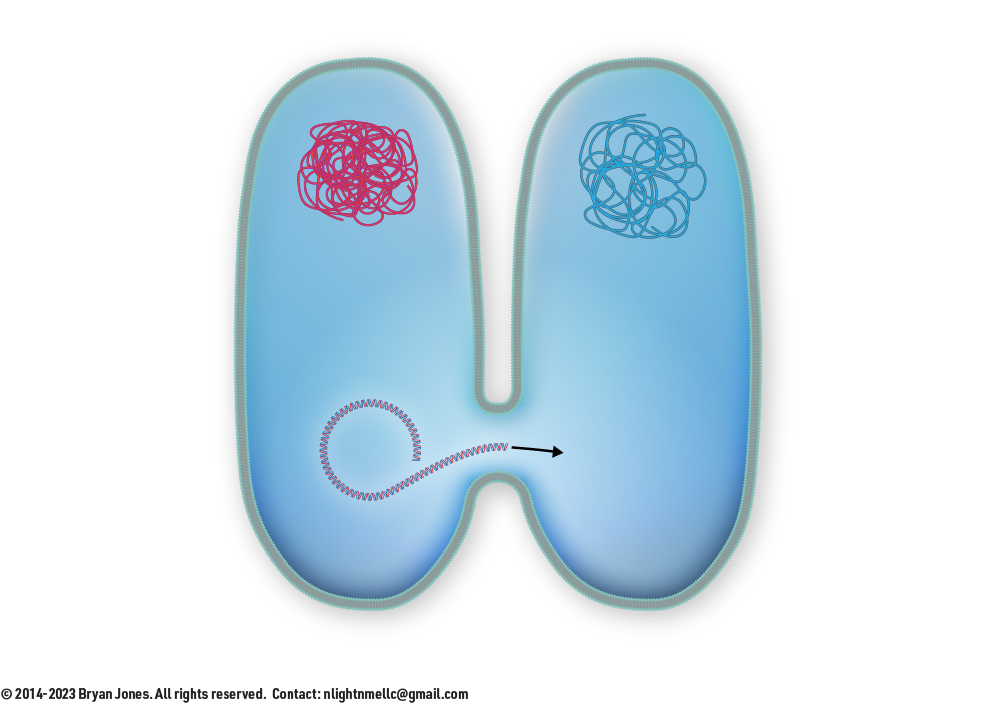
9 | Recombinant cell reproduces normally producing a recombinant cell with a genotype different from cell A and cell B.
Step 9
Generalized Transduction step 9
In summary, generalized transduction is a process by which a bacteriophage accidentally packages a piece of bacterial DNA into a phage particle and transfers it to a new host cell during infection. This process can result in the transfer of a new gene into the genome of the recipient cell, leading to genetic diversity and evolution of bacterial populations.
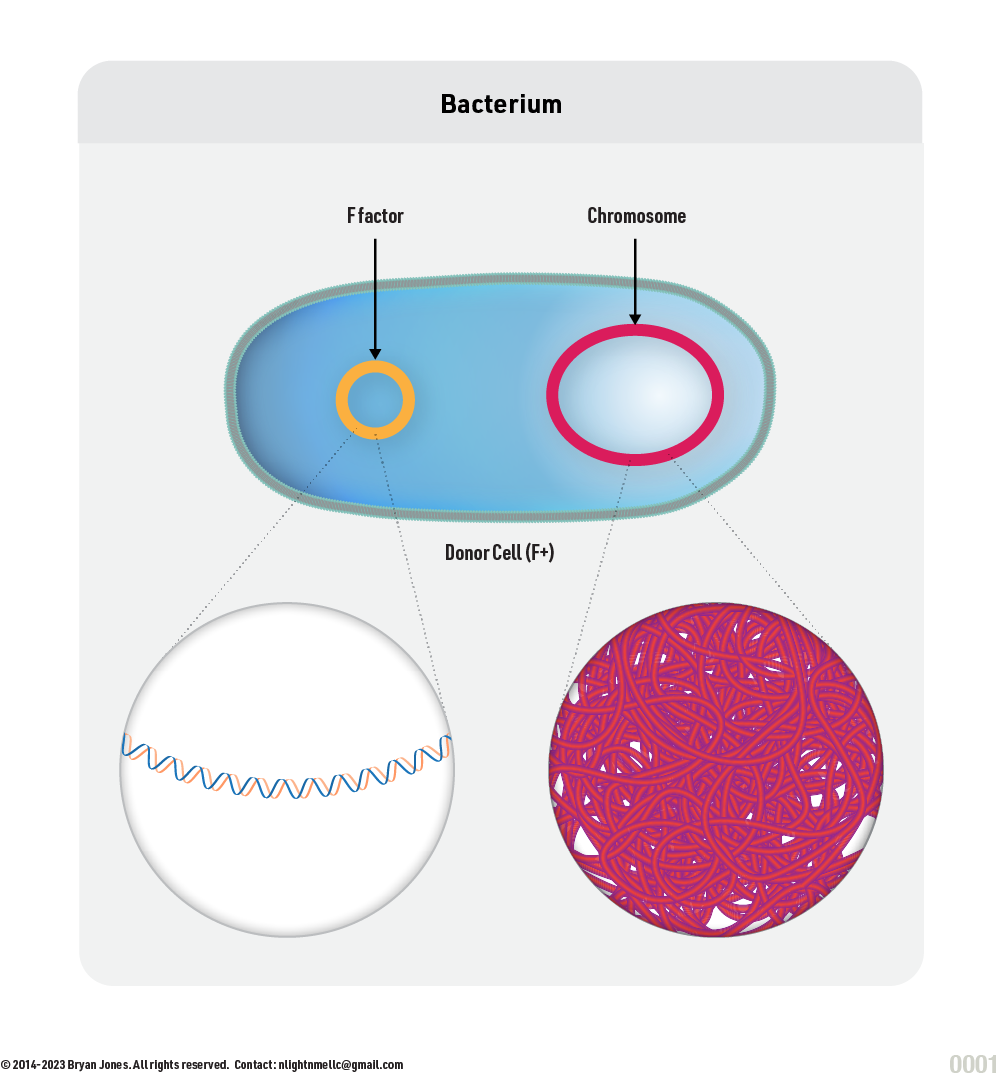
Conjugation
A mechanism of gene transfer
Conjugation is an important mechanism of genetic exchange in bacteria, allowing for the spread of antibiotic resistance, virulence factors, and other traits that contribute to bacterial adaptation and survival.
Conjugation Overview
step 2
Conjugation is a mechanism of horizontal gene transfer in bacteria that involves the transfer of genetic material from one bacterial cell to another through a conjugative pilus. The transfer of genetic material occurs between two cells in contact, where the donor cell transfers a copy of a plasmid or a part of its chromosome to the recipient cell.
F-factor
The F-factor (also called the fertility factor) is a plasmid found in certain bacteria, including E. coli. It contains a set of genes that are responsible for initiating the process of conjugation, which is a form of horizontal gene transfer between bacterial cells. When an F-factor integrates into the chromosome of a bacterial cell, it becomes a part of the cell's genetic material, and it can be passed down to subsequent generations.
Steps involved in the integration of an F-factor into a bacterial chromosome:
The F-factor plasmid enters the bacterial cell via conjugation, a process in which a donor bacterial cell transfers a copy of the F-factor to a recipient cell.
The F-factor plasmid replicates independently of the bacterial chromosome, and the new copy of the plasmid segregates into one of the daughter cells during cell division.
The F-factor plasmid contains a site-specific recombination system that enables it to integrate into the chromosome of the bacterial cell. The recombination system consists of two enzymes: Integrase and Excisionase.
The Integrase enzyme catalyzes the insertion of the F-factor into a specific site on the bacterial chromosome called the attB site, which is recognized by the F-factor as the target for integration.
The Excisionase enzyme is responsible for the excision of the F-factor from the chromosome, allowing it to return to its episomal state and resume conjugation.
Overall of F-factor integration
Overview
1 | Moves toward Chromosome with help of microtubules.
step 1
2 | Bumps into Chromosome, enzyme cleaves DNA.
step 2
3 | Enzyme repairs cleaved portions combining F-factor with Chromosome.
step 3
Conjugation | High Frequency Recombination (Hfr)
When an F-factor integrates into the bacterial chromosome, it creates a high-frequency of recombination in the cell because it enables the transfer of large segments of the bacterial chromosome during conjugation.
The F-factor contains genes that are responsible for the production of a pilus, which is a structure that enables physical contact between donor and recipient cells.
Once the pilus is formed, the F-factor initiates a rolling-circle replication mechanism that results in the transfer of a single-stranded copy of the F-factor to the recipient cell.
During this process, the F-factor can also pick up adjacent segments of the bacterial chromosome, leading to the transfer of large segments of genetic material. This can result in the rapid spread of antibiotic resistance genes or other beneficial traits throughout bacterial populations.
Steps involved in conjugation transfer:
The donor cell synthesizes a conjugative pilus, which extends outwards from the cell and attaches to a recipient cell.
The pilus then retracts, pulling the donor and recipient cells closer together until they are in direct contact.
A specialized protein called relaxase, encoded by the plasmid or chromosome of the donor cell, binds to the origin of transfer (oriT) site on the DNA.
The relaxase then cleaves one strand of the DNA at the oriT site, creating a nick in the plasmid or chromosome.
The nicked strand is then transferred to the recipient cell, where it is used as a template for the synthesis of a complementary strand.
The donor cell synthesizes a new strand of DNA to replace the transferred strand, resulting in the formation of a circular DNA molecule.
The recipient cell, now containing the transferred DNA, may integrate it into its own genome or use it as a template for the synthesis of new proteins or other molecules.
Advanced Topics
Not all topics listed here have been covered in this chapter, you should begin to understand that Nucleic Acids are versatile and provide cells means to control and maintain themselves. It is a self-replicating compound.
Action
Description
Purines and Pyrimidines
Types of nitrogenous bases in nucleotides.
Base Pairing
Complementary bonding between DNA bases.
Structure of DNA
Double helix configuration of deoxyribonucleic acid.
Biosynthesis of Purines and Pyrimidines
The process of creating purine and pyrimidine bases.
Purine Interconversions
Conversion of one purine base into another.
Catabolism of Purine and Pyrimidine Nucleotides
Breakdown of purine and pyrimidine nucleotides.
Salvage Pathway
Reusing bases and nucleosides in nucleotide synthesis.
graph TD
%% Theming and Classes
classDef chromatin fill:#f3e8fd,stroke:#9333ea,stroke-width:2px,color:#4c1d95,rx:6px,ry:6px
classDef transcription fill:#e0f2fe,stroke:#0284c7,stroke-width:2px,color:#0c4a6e,rx:6px,ry:6px
classDef splicing fill:#ccfbf1,stroke:#0d9488,stroke-width:2px,color:#134e4a,rx:6px,ry:6px
classDef rnaMods fill:#fef08a,stroke:#ca8a04,stroke-width:2px,color:#713f12,rx:6px,ry:6px
classDef transport fill:#ffedd5,stroke:#ea580c,stroke-width:2px,color:#7c2d12,rx:6px,ry:6px
classDef translation fill:#dcfce7,stroke:#16a34a,stroke-width:2px,color:#14532d,rx:6px,ry:6px
classDef extracellular fill:#fce7f3,stroke:#db2777,stroke-width:2px,color:#831843,rx:6px,ry:6px
classDef feedback fill:#fee2e2,stroke:#dc2626,stroke-width:2px,color:#7f1d1d,rx:6px,ry:6px
classDef decision fill:#ffffff,stroke:#475569,stroke-width:2px,color:#0f172a,shape:diamond
A["3D Genome Architecture"]:::chromatin --> B["Epigenetic Landscape"]:::chromatin
B --> C["Alternative Transcription Start Sites"]:::transcription
C --> D["Transcription Initiation"]:::transcription
D --> E["Pol II Elongation Kinetics"]:::transcription
E --> F{"Elongation Speed"}:::decision
F -- Slow --> G["Enhanced Exon Inclusion"]:::transcription
F -- Fast --> H["Exon Skipping"]:::transcription
G --> I["Co-Transcriptional RNA Folding"]:::transcription
H --> I
I --> J["Spliceosome Assembly"]:::splicing
J --> K{"Splicing Mode"}:::decision
K -- Cis-Splicing --> L["Canonical / Alternative Isoforms"]:::splicing
K -- Trans-Splicing --> M["Chimeric RNA"]:::splicing
K -- Read-Through --> N["Gene Fusion RNA"]:::splicing
L --> O["RNA Editing"]:::rnaMods
M --> O
N --> O
O --> P["Epitranscriptomic Modification (Graded m6A States)"]:::rnaMods
P --> Q["Alternative Polyadenylation"]:::rnaMods
P --> R["LLPS Condensates"]:::rnaMods
Q --> S{"Nuclear Quality Control"}:::decision
S -- PTC --> T["NMD"]:::transport
S -- Improper --> U["Nuclear Retention"]:::transport
S -- Valid --> V["Export-Competent RNP"]:::transport
R --> U
R --> V
R --> W["Stress Granules / P-Bodies"]:::translation
V --> X["Nuclear Export via NPC"]:::transport
V --> Y["Extracellular Vesicle Packaging"]:::extracellular
X --> Z["Ribosome Scanning"]:::translation
Y --> AA["Intercellular Gene Regulation"]:::extracellular
Z --> AB{"Initiation Mode"}:::decision
AB -- AUG --> AC["Canonical ORF"]:::translation
AB -- Near-Cognate --> AD["Alternative ORF"]:::translation
AB -- RAN --> AE["Multi-Frame Translation"]:::translation
AC --> AF["Protein Output"]:::translation
AD --> AF
AE --> AF
AF --> AG["Feedback to Chromatin / Splicing"]:::feedback
AG -->|Regulatory Loop| B
%% Interactive Clicks
click A call handleNodeClick("A")
click B call handleNodeClick("B")
click C call handleNodeClick("C")
click D call handleNodeClick("D")
click E call handleNodeClick("E")
click F call handleNodeClick("F")
click G call handleNodeClick("G")
click H call handleNodeClick("H")
click I call handleNodeClick("I")
click J call handleNodeClick("J")
click K call handleNodeClick("K")
click L call handleNodeClick("L")
click M call handleNodeClick("M")
click N call handleNodeClick("N")
click O call handleNodeClick("O")
click P call handleNodeClick("P")
click Q call handleNodeClick("Q")
click R call handleNodeClick("R")
click S call handleNodeClick("S")
click T call handleNodeClick("T")
click U call handleNodeClick("U")
click V call handleNodeClick("V")
click W call handleNodeClick("W")
click X call handleNodeClick("X")
click Y call handleNodeClick("Y")
click Z call handleNodeClick("Z")
click AA call handleNodeClick("AA")
click AB call handleNodeClick("AB")
click AC call handleNodeClick("AC")
click AD call handleNodeClick("AD")
click AE call handleNodeClick("AE")
click AF call handleNodeClick("AF")
click AG call handleNodeClick("AG")
System Overview
The Flow of Gene Expression
Gene expression is not a simple linear path, but a highly dynamic and deeply regulated multi-step journey. It begins within the complex spatial environment of the nucleus and ends with a functional protein in the cytoplasm.
This architecture involves several critical Decision Hubs:
Transcription Kinetics: The speed of RNA Polymerase II influences exon inclusion.
Splicing Modes: Generates vast proteomic diversity through alternative isoforms.
Nuclear Quality Control: Ensures only properly processed transcripts exit the nucleus.
Interactive Diagram
Click on any node in the flowchart to explore the specific biological mechanisms, regulatory factors, and quick facts governing that step.
Buttons provide an option to modify the way text is displayed. Users can choose from a range of settings that alter the font size, style, color, spacing, and other visual aspects of the text.
Modifications can be particularly helpful for individuals who have difficulty reading small text or distinguishing between certain colors, or for those who simply prefer a different visual presentation. Overall, the buttons serve as a useful tool for customizing text to meet the needs and preferences of different users.
Fonts may take time to load
Load Original Fonts
Load Head
Load Futura
Load Meta
Load Margin
Load Aria Pro
Load Le Monde Courier
Load Merriweather
Load Leo
Load Bree
Load Bernhard
Load Fira Sans
Load Native
Load Gitan
Beta
Available for sections: States of Matter, Chemical Reactions
Beta Version 1.0
available for sections: States of Matter, Chemical Reactions
These filters apply to live previews and SVG exports globally.
0px
Style Presets
Copy your current global style configuration to share, or paste a code below to apply it site-wide.
Beta version 1.2
GenomicArchitectv2.0 Master
The Regulatory Code
The genome is a sophisticated information-processing machine. Through a complex cis-regulatory grammar of Promoters, Enhancers, and Response Elements, DNA orchestrates life with precise spatial and temporal control.
Simulator Modules0
Access the high-fidelity structural physics engines developed for specific genomic mechanics.
Active Engines8 / 8
UID: 1029384756Mod 02
TF Architecture
Gaussian DNA bending physics (0°–110°) for protein-DNA docking.
HELIX-WARP ENGINE v2.1
UID: 5564738291Mod 03
Epigenetic Landscape
Interactive chromatin density simulator for Euchromatin/Heterochromatin shift.
NUCLEO-PACK ENGINE v1.0
UID: 2231456789Mod 05
Initiation Mechanics
50-bp Gaussian physics engine detailing the 80° TBP-induced distortion.
TBP-ANCHOR ENGINE v2.0
UID: 4455667788Mod 08
UTR Regulation
Full-width closed-loop translation engine and miRNA+RISC degradation.
TRANSLATION-LOOP ENGINE v2.0
Linear Genome Navigator
Explore the anatomy of a gene locus. This interactive model visualizes the spatial relationships essential for gene regulation. Click any element to inspect its molecular function.
5'
3'
Select an Element
Interactive Model
Click on the colored blocks in the strand above to reveal their specific biological functions, location relative to the Transcription Start Site (TSS), and their role in the regulatory grammar.
Position--
Key Interaction--
Combinatorial Logic Engine
Simulating the physical assembly of the Pre-Initiation Complex. Activate toggles to observe specific factors binding, structural enhancer looping, and real-time mRNA transcription kinetics.
Expression OutputSILENCED
Chromatin Condensed / Locus Inaccessible
Enhancer Element
ACT
Core Promoter
GTFs
REP
Coding Sequence (Exons)
Pol II
Mediator Bridge
1. Chromatin StateCLOSED
2. Basal Complex
3. Distal Activator
4. Mediator Bridge
5. Repressor Protein
Element Encyclopedia
Comprehensive inventory of functional sequence elements.
Structural Analytics Dashboard
Quantitative breakdown of the regulatory landscape, contrasting functional roles and spatial distribution across the genome.
Functional Distribution
Relative frequency of Initiation vs. Modulation elements.
Spatial Architecture
Comparison of proximal vs. distal locations relative to the TSS.

























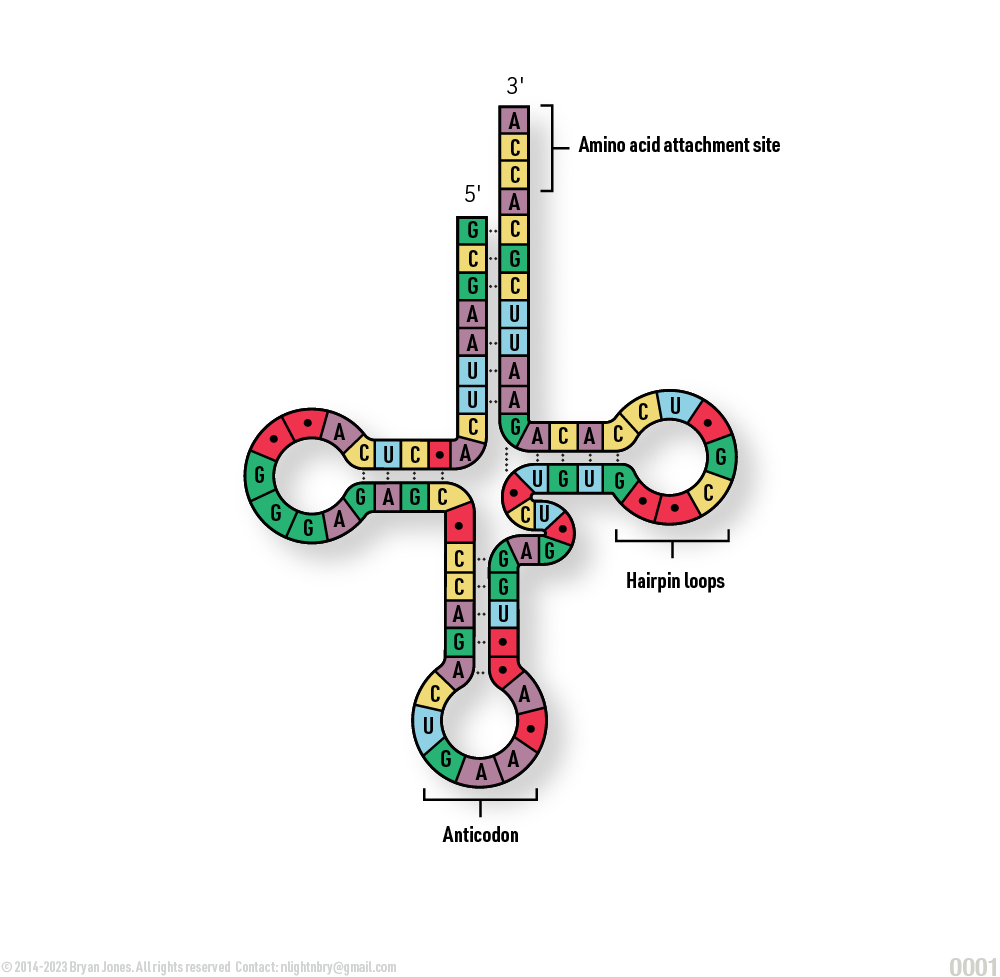


























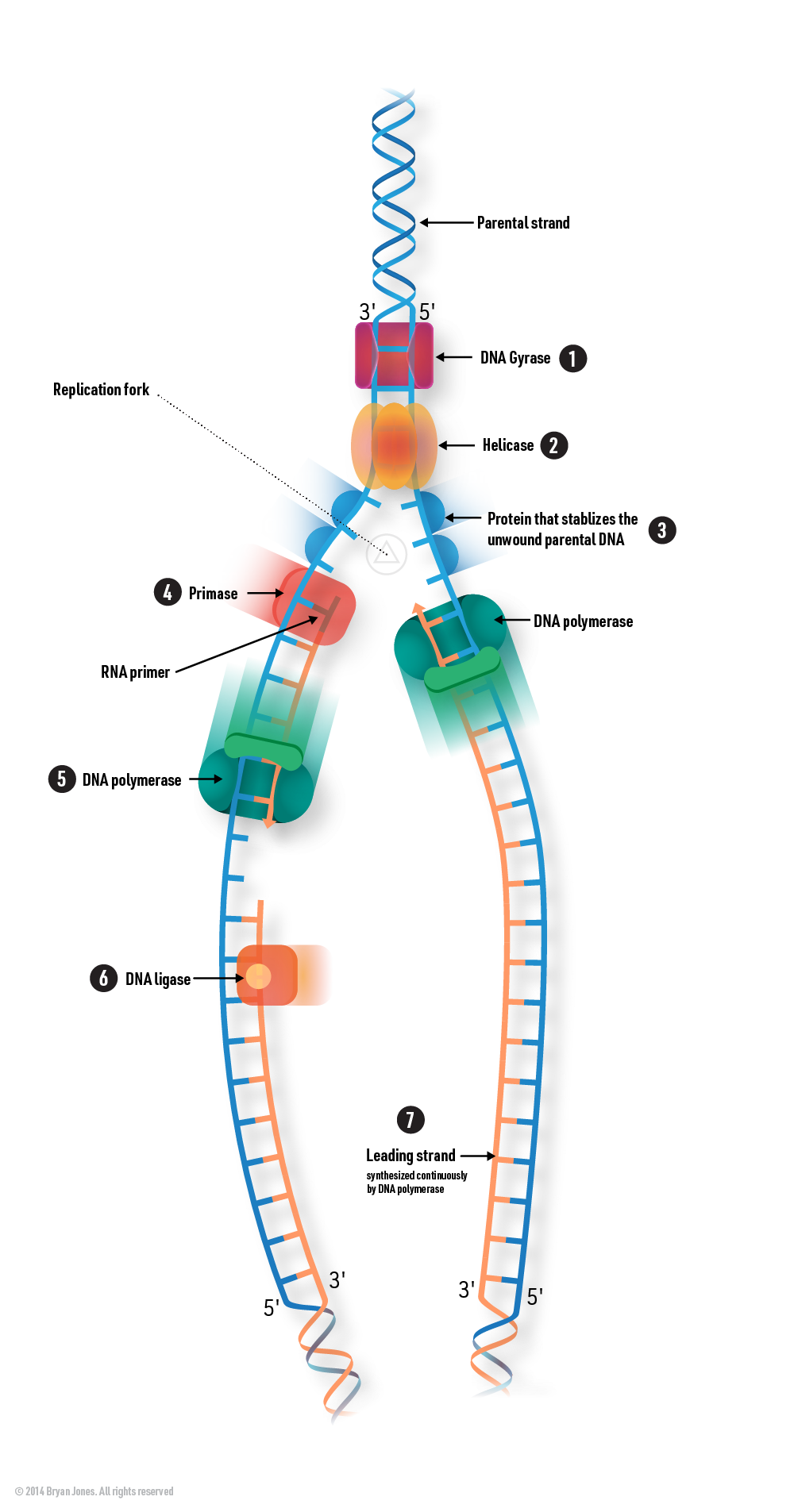
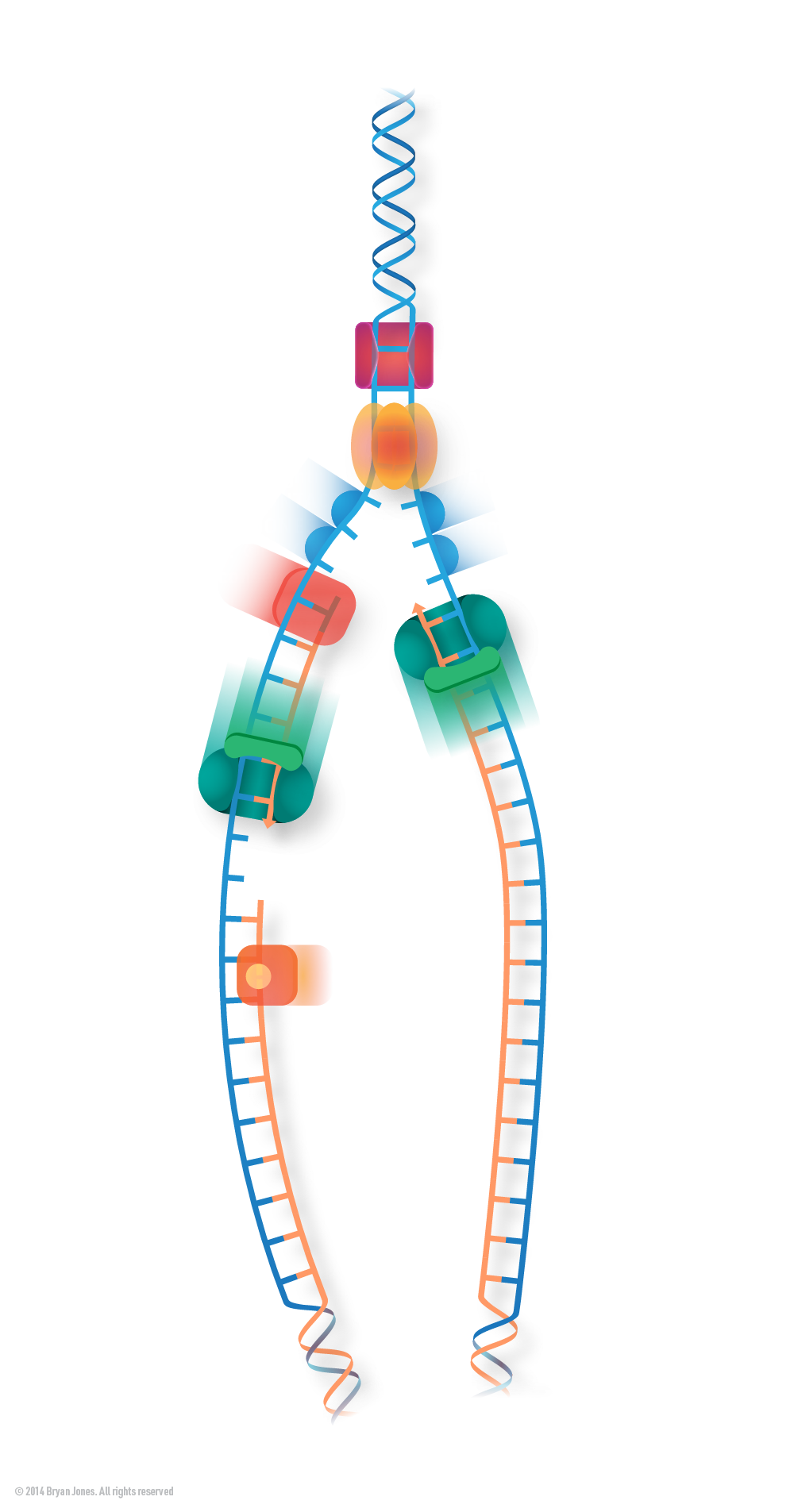






{kind=link}